
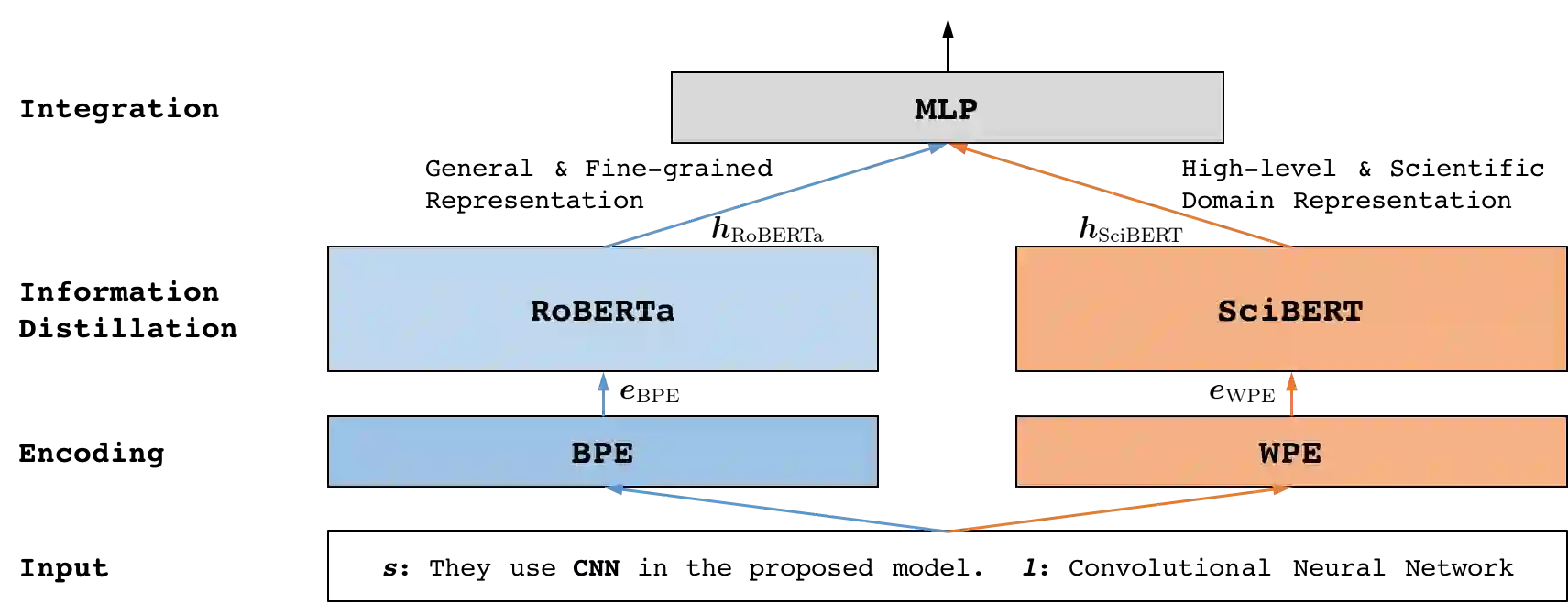
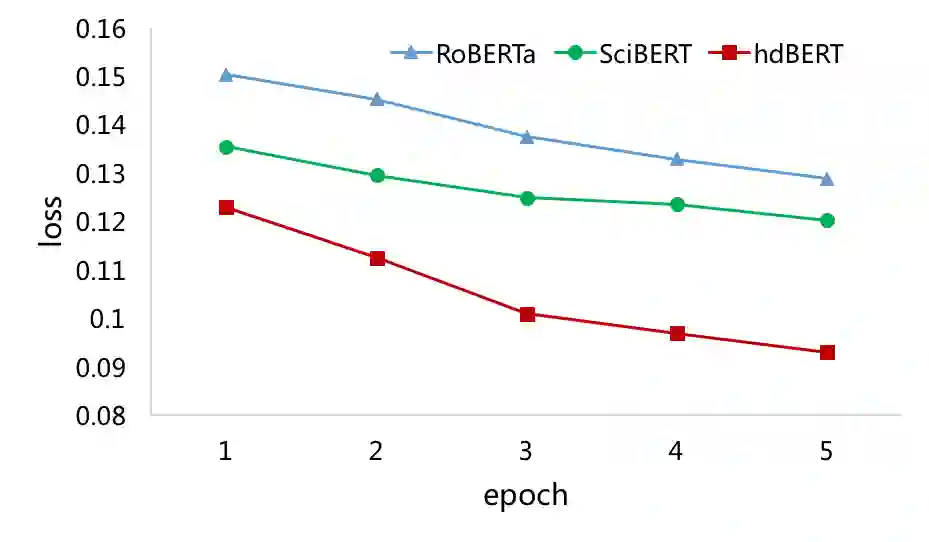
An obstacle to scientific document understanding is the extensive use of acronyms which are shortened forms of long technical phrases. Acronym disambiguation aims to find the correct meaning of an ambiguous acronym in a given text. Recent efforts attempted to incorporate word embeddings and deep learning architectures, and achieved significant effects in this task. In general domains, kinds of fine-grained pretrained language models have sprung up, thanks to the largescale corpora which can usually be obtained through crowdsourcing. However, these models based on domain agnostic knowledge might achieve insufficient performance when directly applied to the scientific domain. Moreover, obtaining large-scale high-quality annotated data and representing high-level semantics in the scientific domain is challenging and expensive. In this paper, we consider both the domain agnostic and specific knowledge, and propose a Hierarchical Dual-path BERT method coined hdBERT to capture the general fine-grained and high-level specific representations for acronym disambiguation. First, the context-based pretrained models, RoBERTa and SciBERT, are elaborately involved in encoding these two kinds of knowledge respectively. Second, multiple layer perceptron is devised to integrate the dualpath representations simultaneously and outputs the prediction. With a widely adopted SciAD dataset contained 62,441 sentences, we investigate the effectiveness of hdBERT. The experimental results exhibit that the proposed approach outperforms state-of-the-art methods among various evaluation metrics. Specifically, its macro F1 achieves 93.73%.
翻译:科学文件理解的一个障碍是广泛使用缩略语,这些缩略语是缩短了长长技术短语的形式。 缩略语模糊不清的目的是在特定文本中找到一个含混不清的缩略语的正确含义。 最近努力试图将文字嵌入和深层学习结构纳入其中,并取得了这一任务的重大效果。 在一般领域,由于通常可以通过众包获得的大型组合,各种精细的预加工语言模型已经涌现出来。然而,这些基于域级知识的模型在直接应用到科学领域时,可能实现的绩效不足。此外,获得大规模高品质的附加说明数据以及代表科学领域高级别语义的正确含义是富有挑战性和昂贵的。在本文件中,我们既考虑域内含字型和具体知识,又提议一种高等级的双向双向双向双向双向双向双向双向双向双向双向双向导体 。首先,我们精心设计的预选模式(ROBTA和SciERT)和S-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-xxxxx-x-x-x-x-xxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem

