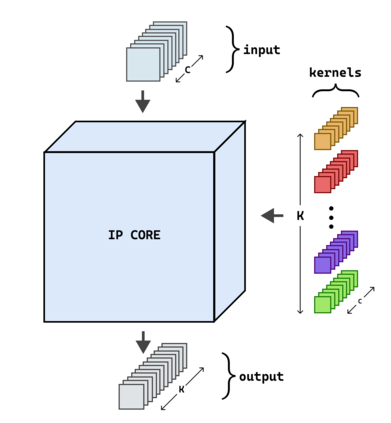
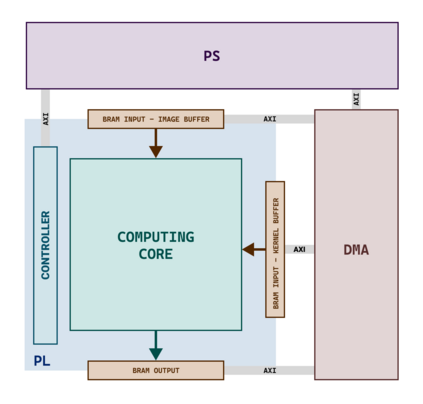
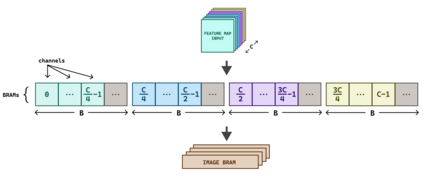
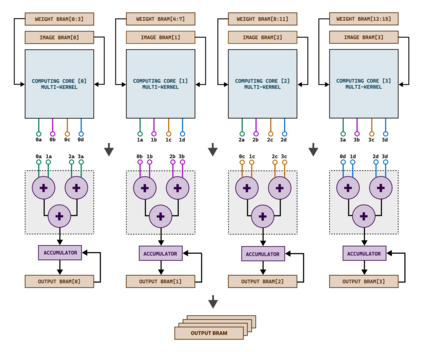
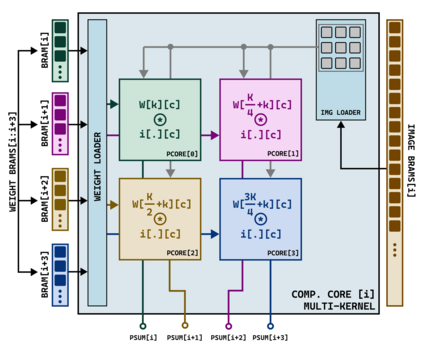
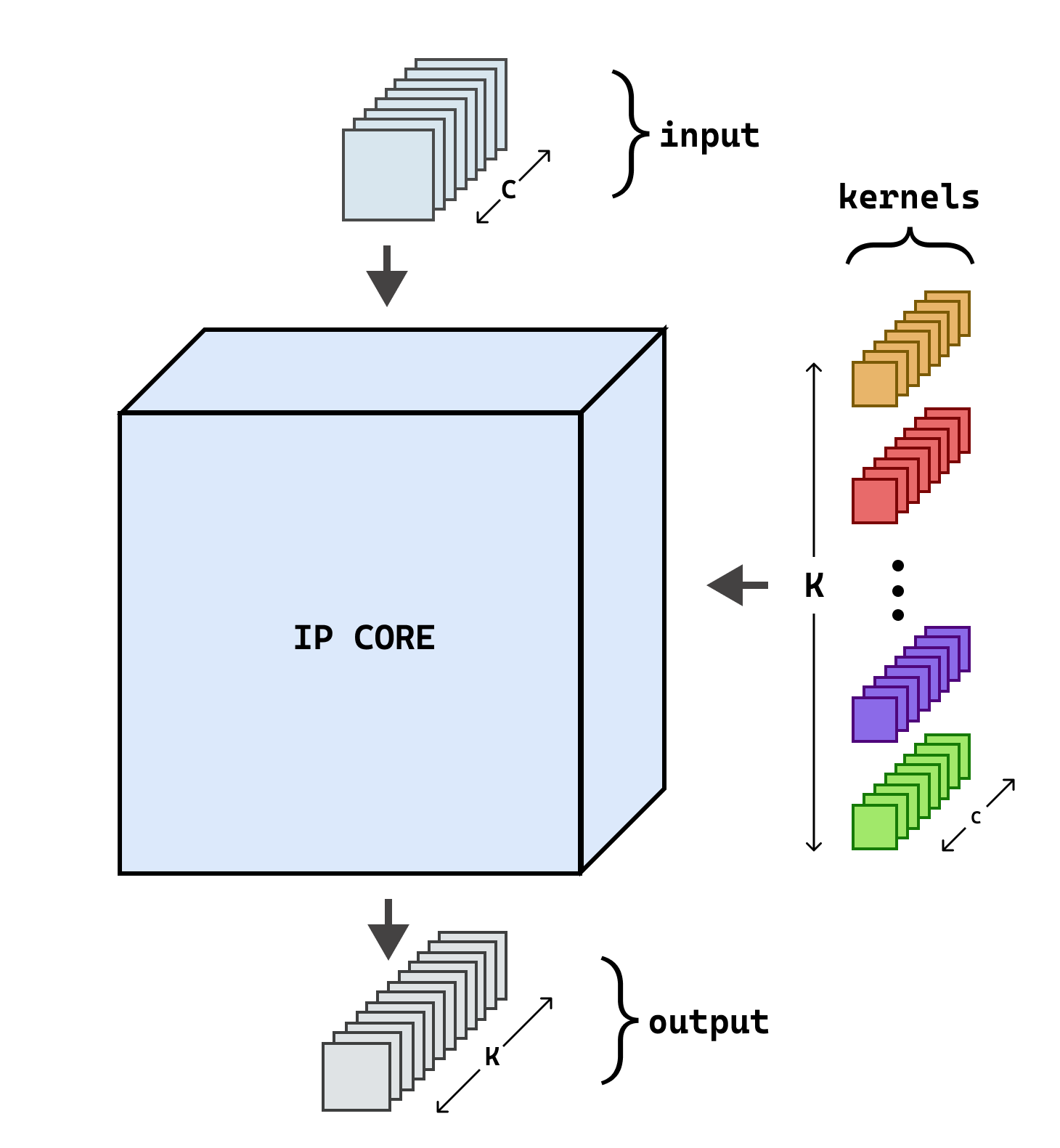
Hardware-based acceleration is an extensive attempt to facilitate many computationally-intensive mathematics operations. This paper proposes an FPGA-based architecture to accelerate the convolution operation - a complex and expensive computing step that appears in many Convolutional Neural Network models. We target the design to the standard convolution operation, intending to launch the product as an edge-AI solution. The project's purpose is to produce an FPGA IP core that can process a convolutional layer at a time. System developers can deploy the IP core with various FPGA families by using Verilog HDL as the primary design language for the architecture. The experimental results show that our single computing core synthesized on a simple edge computing FPGA board can offer 0.224 GOPS. When the board is fully utilized, 4.48 GOPS can be achieved.
翻译:硬件加速是便利许多计算密集型数学操作的广泛尝试。 本文提出一个基于 FPGA 的架构, 以加速进化操作。 这是一个复杂而昂贵的计算步骤, 在许多进化神经网络模型中出现。 我们把设计目标对准标准进化操作, 目的是将产品作为边缘AI解决方案启动。 该项目的目的是生成一个能同时处理进化层的 FPGA IP核心。 系统开发者可以使用 Verilog HDL 来将IP核心与各个 FPGA 家庭一起部署, 将 Verilog HDL 作为该架构的主要设计语言。 实验结果显示, 我们用简单边缘计算机 FPGA 板合成的单一计算核心可以提供 0. 224 GOPS 。 当板被充分利用时, 可以实现 4. 48 GOPS 。