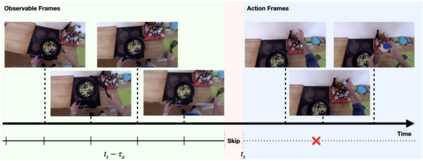
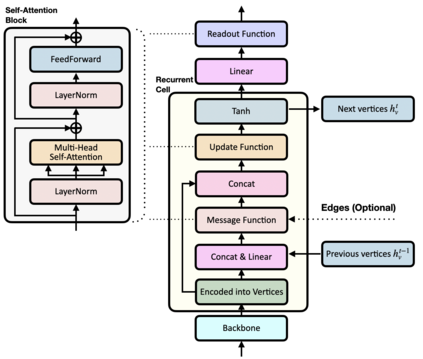
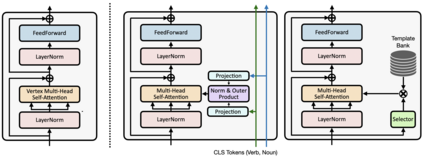
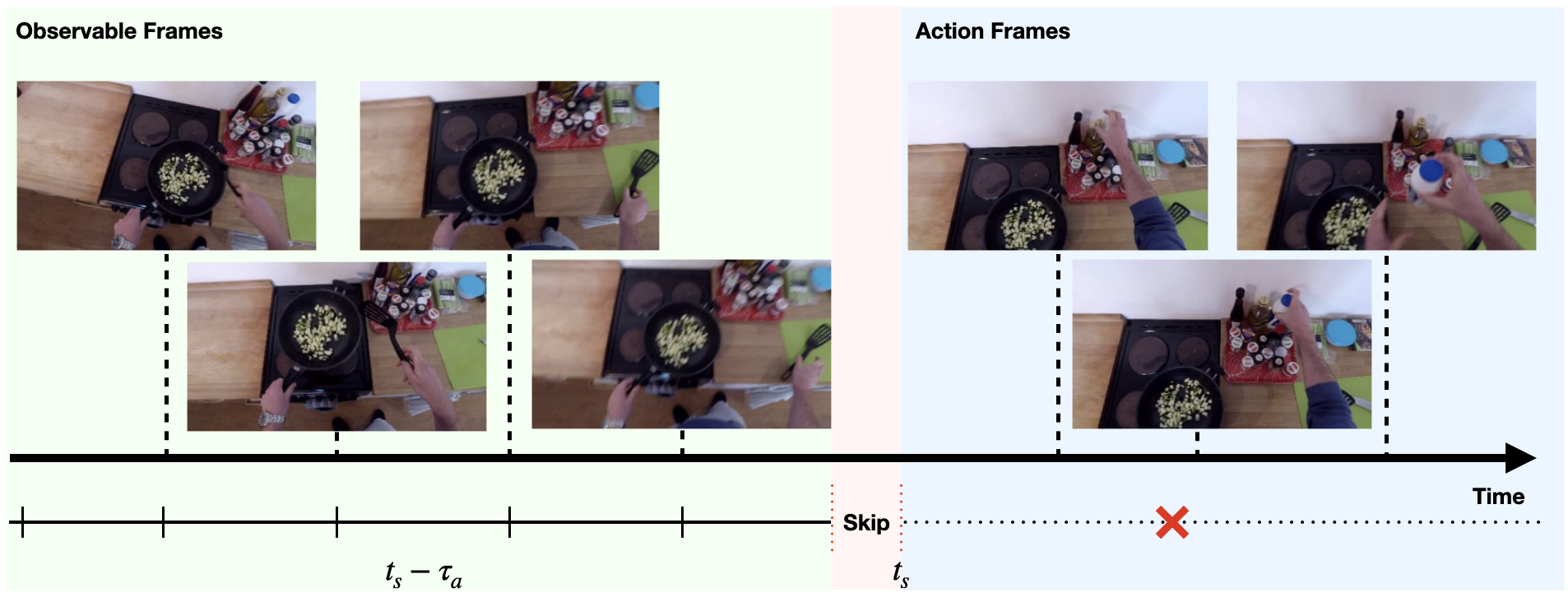
Forecasting future events based on evidence of current conditions is an innate skill of human beings, and key for predicting the outcome of any decision making. In artificial vision for example, we would like to predict the next human action before it happens, without observing the future video frames associated to it. Computer vision models for action anticipation are expected to collect the subtle evidence in the preamble of the target actions. In prior studies recurrence modeling often leads to better performance, the strong temporal inference is assumed to be a key element for reasonable prediction. To this end, we propose a unified recurrence modeling for video action anticipation via message passing framework. The information flow in space-time can be described by the interaction between vertices and edges, and the changes of vertices for each incoming frame reflects the underlying dynamics. Our model leverages self-attention as the building blocks for each of the message passing functions. In addition, we introduce different edge learning strategies that can be end-to-end optimized to gain better flexibility for the connectivity between vertices. Our experimental results demonstrate that our proposed method outperforms previous works on the large-scale EPIC-Kitchen dataset.
翻译:根据当前条件的证据预测未来事件是人类固有的技能,也是预测任何决策结果的关键。例如,在人工的愿景中,我们希望预测下一个人类行动发生之前的下一个人类行动,而不观察与其相关的未来视频框架。预期计算机行动设想模型会收集目标行动序言中的微妙证据。在先前的研究中,反复建模往往会提高性能,假设强大的时间推论是合理预测的一个关键要素。为此,我们提议通过信息传递框架为视频行动预测提供一个统一的重复模型。空间时间的信息流动可以通过顶部和边缘之间的相互作用来描述,而每个进入框架的顶部变化则反映基本动态。我们的模型将自我注意作为每个信息传递功能的构件。此外,我们引入了不同的边缘学习战略,可以最终优化,以获得更好的灵活性。我们的实验结果表明,我们拟议的方法超过了EPIC-Kitchen数据集以前的工程。