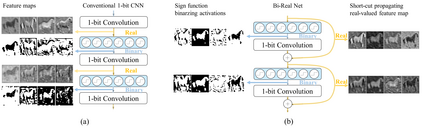
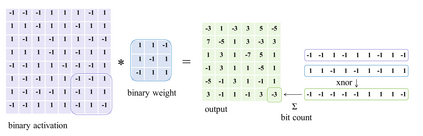
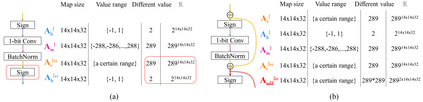
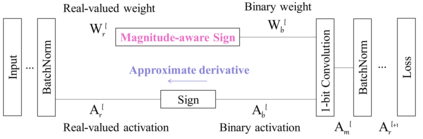
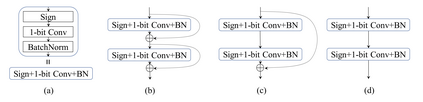
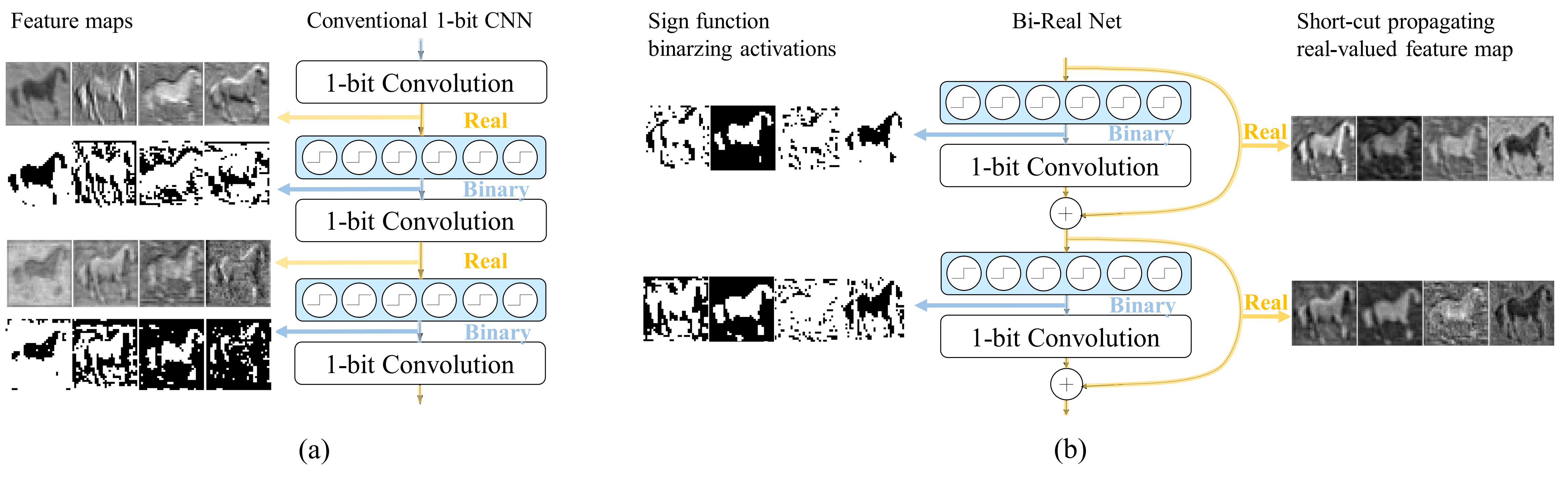
In this work, we study the 1-bit convolutional neural networks (CNNs), of which both the weights and activations are binary. While being efficient, the classification accuracy of the current 1-bit CNNs is much worse compared to their counterpart real-valued CNN models on the large-scale dataset, like ImageNet. To minimize the performance gap between the 1-bit and real-valued CNN models, we propose a novel model, dubbed Bi-Real net, which connects the real activations (after the 1-bit convolution and/or BatchNorm layer, before the sign function) to activations of the consecutive block, through an identity shortcut. Consequently, compared to the standard 1-bit CNN, the representational capability of the Bi-Real net is significantly enhanced and the additional cost on computation is negligible. Moreover, we develop a specific training algorithm including three technical novelties for 1- bit CNNs. Firstly, we derive a tight approximation to the derivative of the non-differentiable sign function with respect to activation. Secondly, we propose a magnitude-aware gradient with respect to the weight for updating the weight parameters. Thirdly, we pre-train the real-valued CNN model with a clip function, rather than the ReLU function, to better initialize the Bi-Real net. Experiments on ImageNet show that the Bi-Real net with the proposed training algorithm achieves 56.4% and 62.2% top-1 accuracy with 18 layers and 34 layers, respectively. Compared to the state-of-the-arts (e.g., XNOR Net), Bi-Real net achieves up to 10% higher top-1 accuracy with more memory saving and lower computational cost. Keywords: binary neural network, 1-bit CNNs, 1-layer-per-block
翻译:在这项工作中,我们研究了1比特的神经神经网络(CNNs),其重量和激活都是二进制的。在效率方面,当前1比特的CNN的分类准确性比在大型数据集(如图像网)上的对应的1比特的CNN模型要差得多。为了尽可能缩小1比特和实际估值的CNN模型之间的性能差距,我们提出了一个新颖的模型,称为Bi-Real网,它将真正的启动(在1比特的螺旋的精度和/或BatchNorm层之后,在信号功能之前)与连续的链块的激活连接起来。虽然是有效的,但目前的1比特1比特的CNN(如图像网)的分类准确性能比对应的1比特的有实际价值的CNNNM模型模型要差得多。此外,我们开发了一个专门的培训算法,包括3比特1比特的技术性的新技术算法。首先,我们从不可辨的硬信号函数的衍生物中获取了近近一点。第二,我们提议用1比标准级的模型化的模型更精确的直径直径直径直径直径直径直达的直径直线。我们建议, 。我们提议在更新了一个比前的网络的模型的模型的模型到比重的内基级的深度的深度的内推算法,在更新了62的内,比重的深度的内基比重的内基比重。我们的内基比重。我们建议,比重的内基到比重的Sir算法。