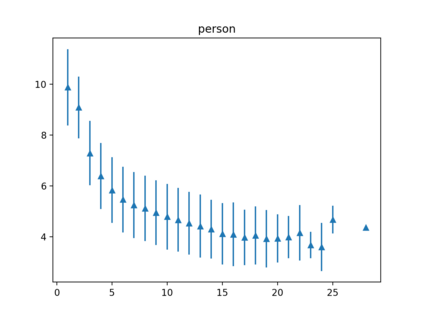
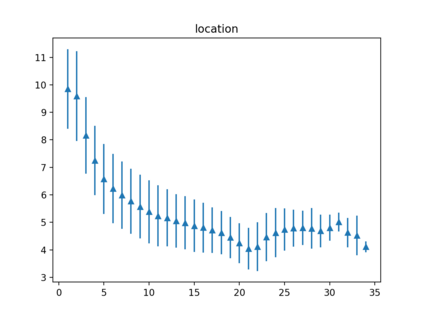
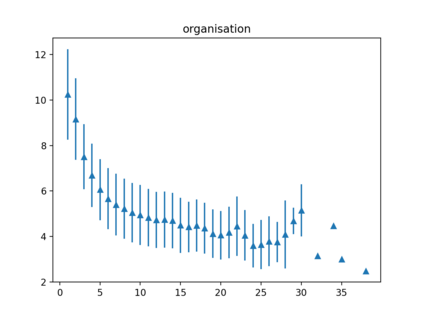
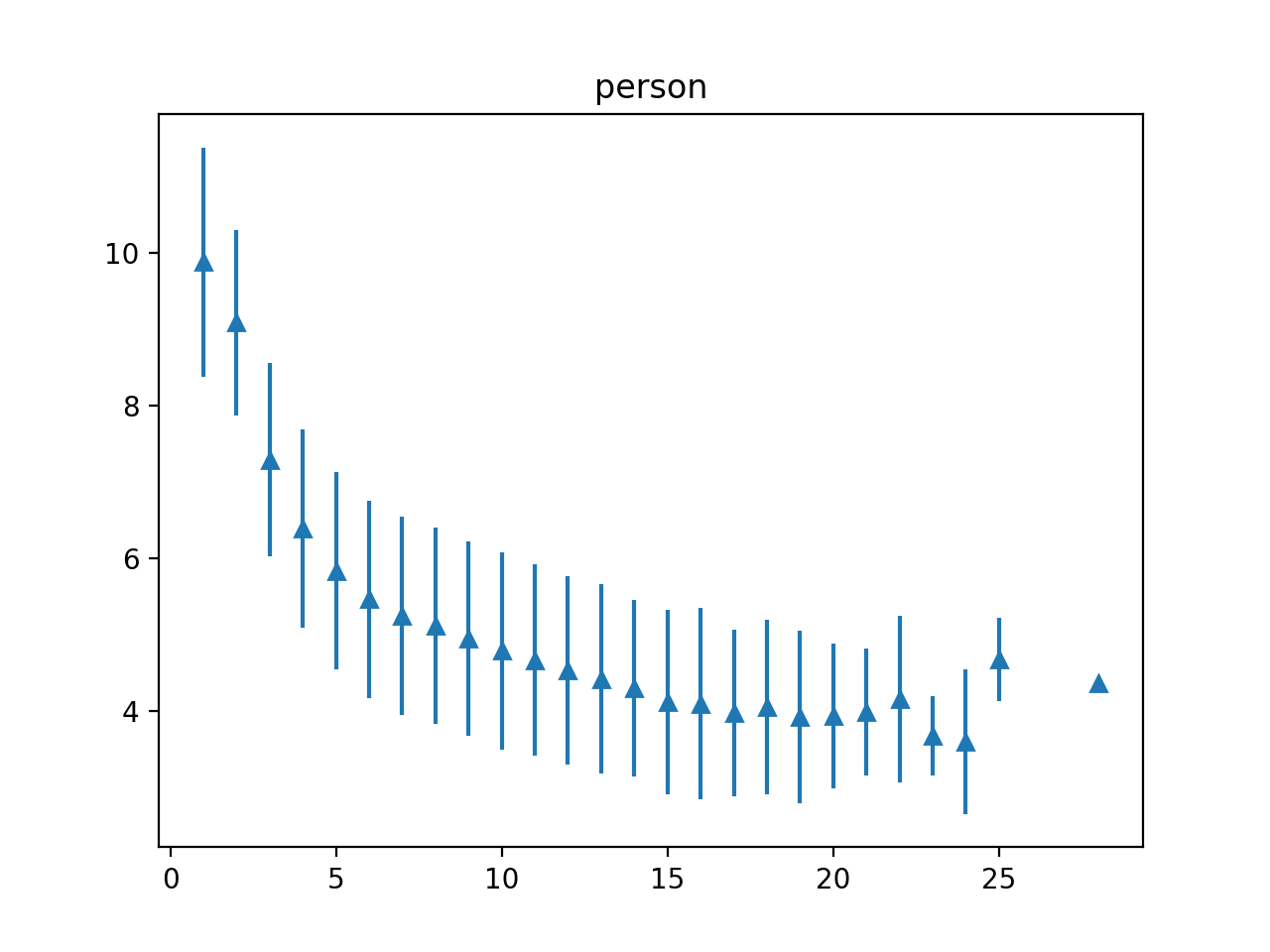
Despite impressive results of language models for named entity recognition (NER), their generalization to varied textual genres, a growing entity type set, and new entities remains a challenge. Collecting thousands of annotations in each new case for training or fine-tuning is expensive and time-consuming. In contrast, humans can easily identify named entities given some simple instructions. Inspired by this, we challenge the reliance on large datasets and study pre-trained language models for NER in a meta-learning setup. First, we test named entity typing (NET) in a zero-shot transfer scenario. Then, we perform NER by giving few examples at inference. We propose a method to select seen and rare / unseen names when having access only to the pre-trained model and report results on these groups. The results show: auto-regressive language models as meta-learners can perform NET and NER fairly well especially for regular or seen names; name irregularity when often present for a certain entity type can become an effective exploitable cue; names with words foreign to the model have the most negative impact on results; the model seems to rely more on name than context cues in few-shot NER.
翻译:尽管命名实体识别(NER)的语言模式取得了令人印象深刻的结果,但是,这些模式的概括性仍是一个挑战。在每一个新的培训或微调新案例中收集数千个说明是昂贵和费时的。相反,人类可以很容易地识别一些简单指示的指定实体。因此,我们在元学习设置中质疑对大型数据集的依赖,并研究用于NER的预先培训的语言模式。首先,我们在零光传输的假设中测试名称实体输入(NET),然后,我们通过提供很少的推断实例来进行NER。我们建议一种方法,在只使用预先培训的模式和报告这些组的结果时,选择可见的和罕见的/未知的名称。结果显示:作为元清除器的自动反向语言模式可以相当顺利地运行NET和NER;当某个实体类型经常出现时,名称的不规则性可以成为有效的可利用提示;与模型无关的词对结果产生最消极的影响;模型似乎更依赖名称而不是缩略图。