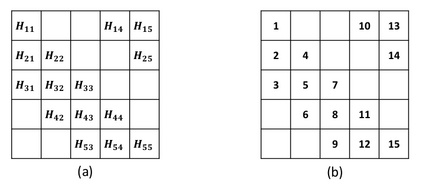
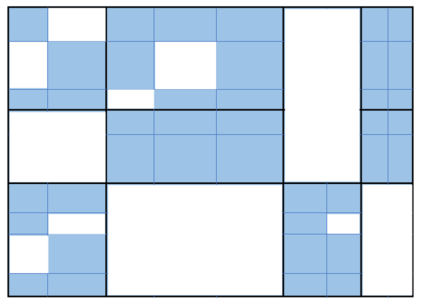
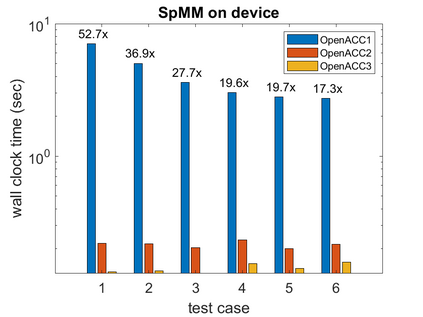
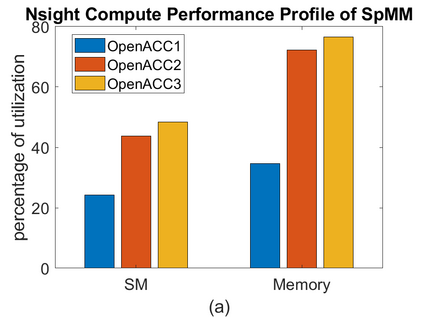
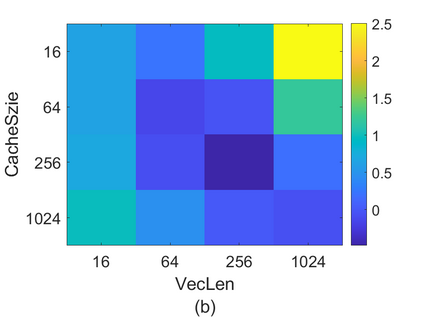
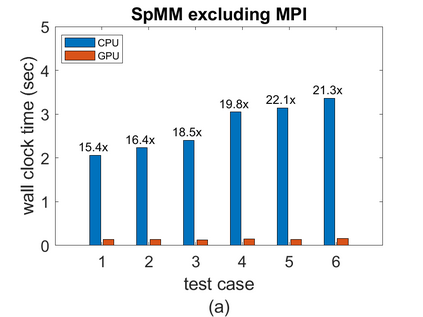
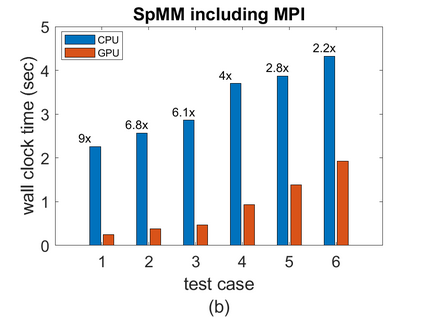
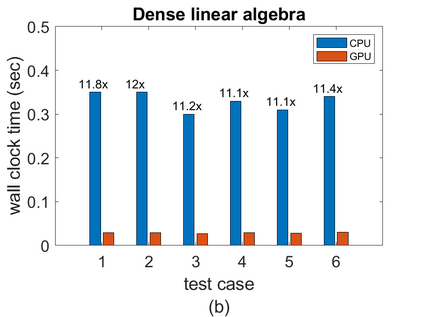
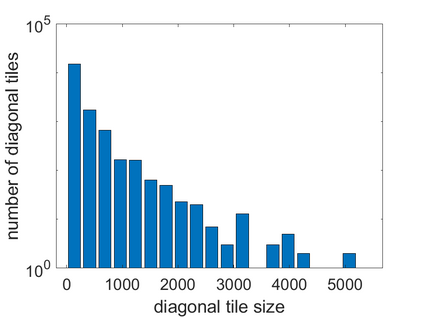
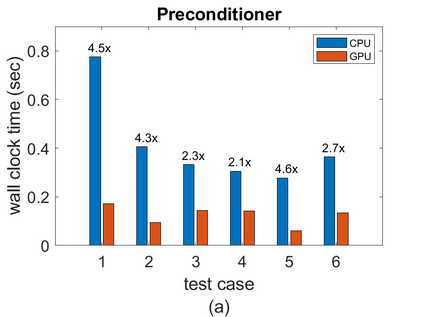
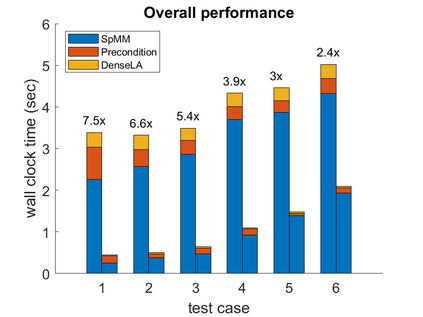
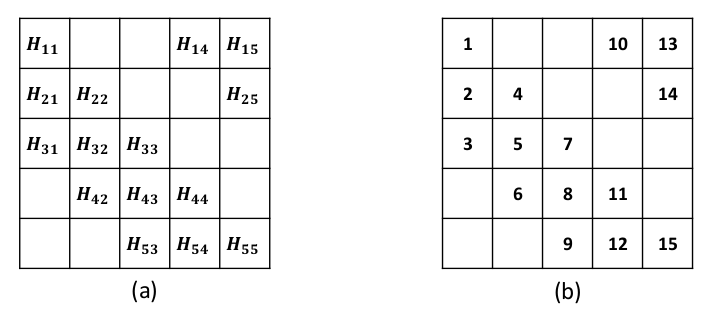
To accelerate the solution of large eigenvalue problems arising from many-body calculations in nuclear physics on distributed-memory parallel systems equipped with general-purpose Graphic Processing Units (GPUs), we modified a previously developed hybrid MPI/OpenMP implementation of an eigensolver written in FORTRAN 90 by using an OpenACC directives based programming model. Such an approach requires making minimal changes to the original code and enables a smooth migration of large-scale nuclear structure simulations from a distributed-memory many-core CPU system to a distributed GPU system. However, in order to make the OpenACC based eigensolver run efficiently on GPUs, we need to take into account the architectural differences between a many-core CPU and a GPU device. Consequently, the optimal way to insert OpenACC directives may be different from the original way of inserting OpenMP directives. We point out these differences in the implementation of sparse matrix-matrix multiplications (SpMM), which constitutes the main cost of the eigensolver, as well as other differences in the preconditioning step and dense linear algebra operations. We compare the performance of the OpenACC based implementation executed on multiple GPUs with the performance on distributed-memory many-core CPUs, and demonstrate significant speedup achieved on GPUs compared to the on-node performance of a many-core CPU. We also show that the overall performance improvement of the eigensolver on multiple GPUs is more modest due to the communication overhead among different MPI ranks.
翻译:为了加速解决在配有通用图形处理器(GPUs)的分布式平行系统上对核物理中许多体积进行计算后产生的大量电子价值问题,我们修改了以前开发的混合MPI/OpenMP在FORTRAN 90 中写成的igensolsol的建筑差异,采用了基于 OpenACC 指令的编程模式。这种方法要求对原始代码做最小的修改,使大规模核结构模拟从分布式中小型多核心CPU系统顺利迁移到分布式GPU系统。然而,为了使基于 OpenAC 的egenSolver系统高效运行,我们需要考虑到多个核心 CPU 和 GPU 设备之间的结构差异。因此,插入 OpenAC 指令的最佳方式可能不同于原有的插入 OpenMP 指令的方式。我们指出,在实施稀有的矩阵矩阵矩阵倍增倍增功能(Spgen-MMM) 方面存在这些差异,这构成了易源Solver系统的主要成本。此外,要使基于预设性和密度线性直线性升升标操作的附加性级之间的其他差异。我们比较了基于GCPUPUPI的运行的运行的运行的性能的性能表现。我们比较了GPUPUPUPUPS的进度比的进度。