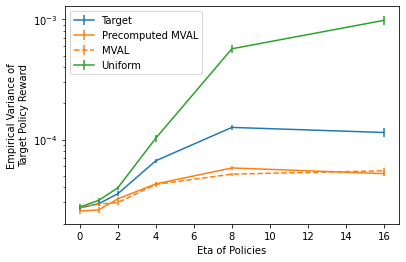
Methods for offline A/B testing and counterfactual learning are seeing rapid adoption in search and recommender systems, since they allow efficient reuse of existing log data. However, there are fundamental limits to using existing log data alone, since the counterfactual estimators that are commonly used in these methods can have large bias and large variance when the logging policy is very different from the target policy being evaluated. To overcome this limitation, we explore the question of how to design data-gathering policies that most effectively augment an existing dataset of bandit feedback with additional observations for both learning and evaluation. To this effect, this paper introduces Minimum Variance Augmentation Logging (MVAL), a method for constructing logging policies that minimize the variance of the downstream evaluation or learning problem. We explore multiple approaches to computing MVAL policies efficiently, and find that they can be substantially more effective in decreasing the variance of an estimator than na\"ive approaches.
翻译:离线 A/B 测试和反事实学习的方法在搜索和建议系统方面迅速得到采用,因为这些方法能够有效地重新使用现有日志数据,然而,仅使用现有日志数据有根本的局限性,因为这些方法中常用的反事实估计器在伐木政策与所评价的目标政策大不相同时,可能会有很大的偏差和很大的差异。为了克服这一局限性,我们探讨如何设计数据收集政策,以最有效的方式增加现有土匪反馈数据集,同时为学习和评价提供额外的观察。为此,本文件介绍了最低差异扩大日志(MIVAL),这是构建伐木政策的一种方法,可以最大限度地减少下游评价或学习问题的差异。我们探索多种方法来高效计算估量政策,发现它们比“na\” 方法在减少估量器差异方面更为有效。