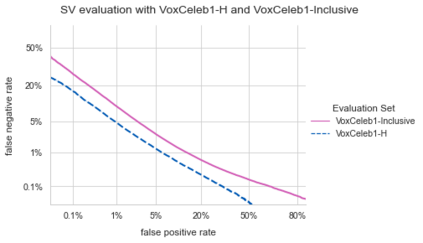
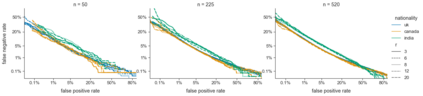
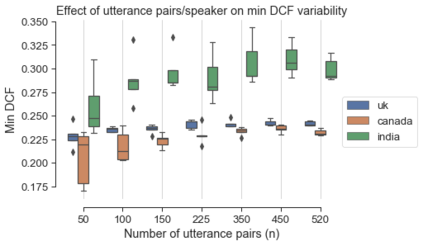
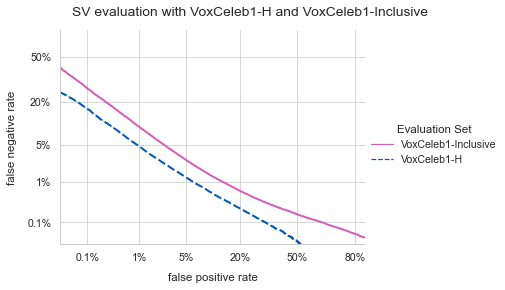
Speaker verification (SV) provides billions of voice-enabled devices with access control, and ensures the security of voice-driven technologies. As a type of biometrics, it is necessary that SV is unbiased, with consistent and reliable performance across speakers irrespective of their demographic, social and economic attributes. Current SV evaluation practices are insufficient for evaluating bias: they are over-simplified and aggregate users, not representative of real-life usage scenarios, and consequences of errors are not accounted for. This paper proposes design guidelines for constructing SV evaluation datasets that address these short-comings. We propose a schema for grading the difficulty of utterance pairs, and present an algorithm for generating inclusive SV datasets. We empirically validate our proposed method in a set of experiments on the VoxCeleb1 dataset. Our results confirm that the count of utterance pairs/speaker, and the difficulty grading of utterance pairs have a significant effect on evaluation performance and variability. Our work contributes to the development of SV evaluation practices that are inclusive and fair.
翻译:语音校验(SV)提供了数十亿个语音辅助装置,具有出入控制功能,并确保语音驱动技术的安全。作为一种生物鉴别技术,SV必须是不带偏见的,无论发言者的人口、社会和经济属性如何,所有发言者都具有一致和可靠的性能。目前的SV评价做法不足以评价偏见:他们使用过于简单和综合,不代表实际使用情景,错误的后果不计其数。本文件提出了建立SV评价数据集的设计准则,以弥补这些缺陷。我们提议了对配对词难分级的方法,并提出了生成包容性的SV数据集的算法。我们在VoxCeleb1数据集的一系列实验中以经验验证了我们提出的方法。我们的结果证实,对配对/代言的数数和对配方的难分对评价业绩和变异性产生了重要影响。我们的工作有助于SV评价做法的发展,这种评价是包容性的和公平的。