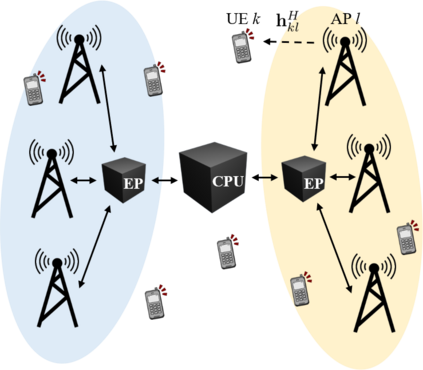
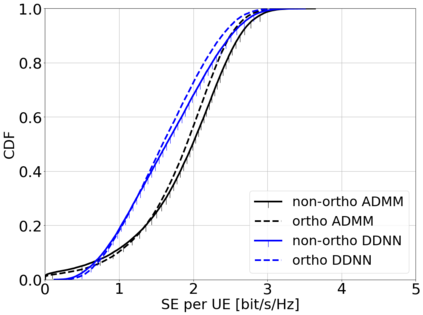
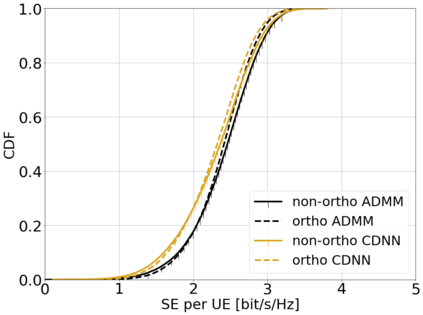
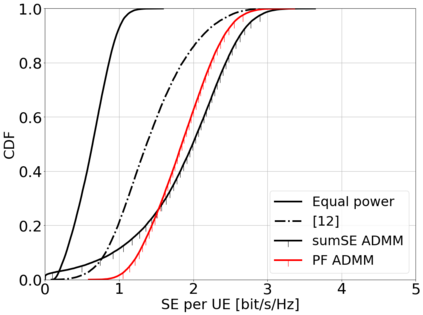
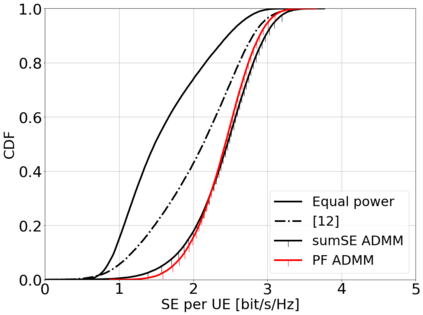
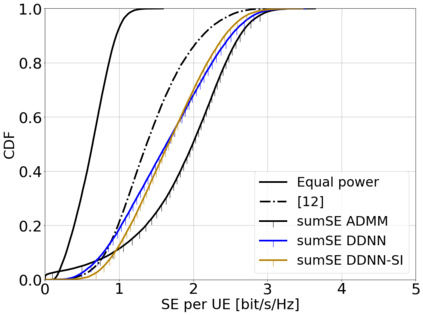
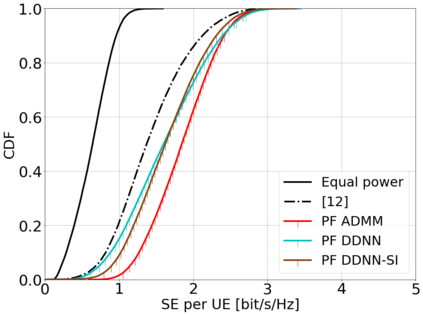
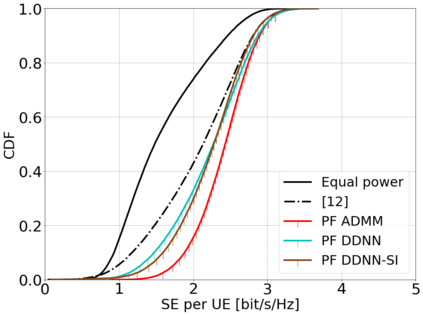
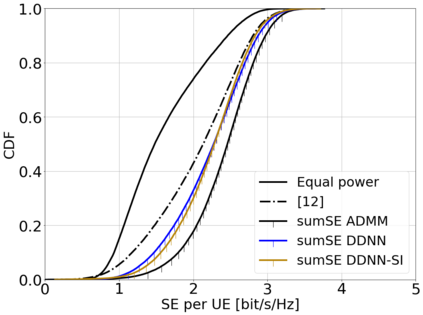
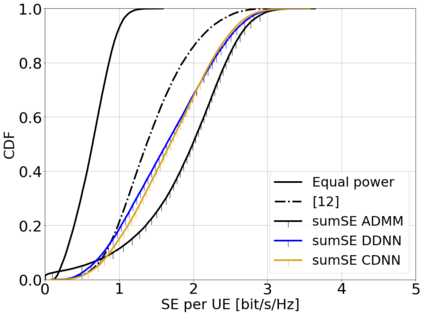
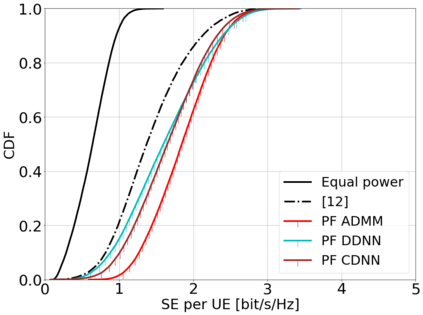
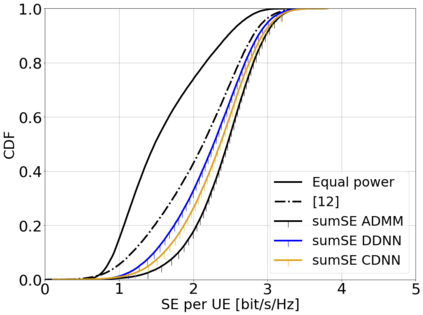
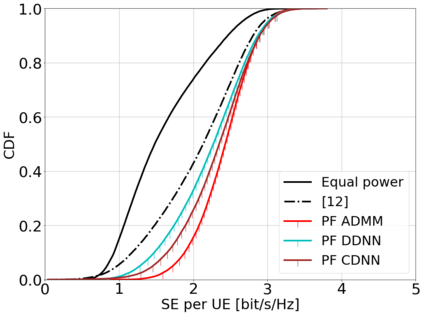
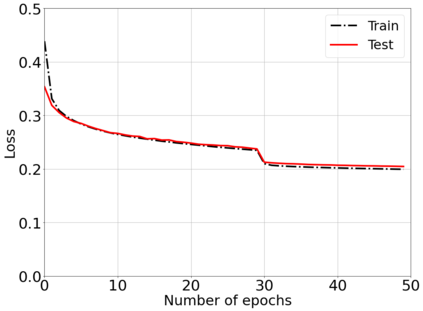
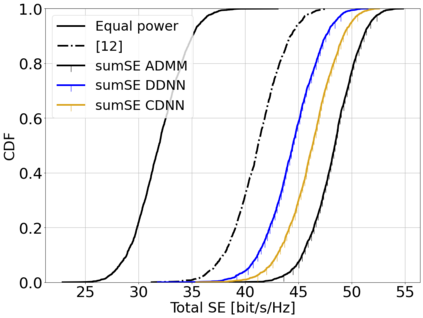
This paper considers a cell-free massive multiple-input multiple-output (MIMO) system that consists of a large number of geographically distributed access points (APs) serving multiple users via coherent joint transmission. The downlink performance of the system is evaluated, with maximum ratio and regularized zero-forcing precoding, under two optimization objectives for power allocation: sum spectral efficiency (SE) maximization and proportional fairness. We present iterative centralized algorithms for solving these problems. Aiming at a less computationally complex and also distributed scalable solution, we train a deep neural network (DNN) to approximate the same network-wide power allocation. Instead of training our DNN to mimic the actual optimization procedure, we use a heuristic power allocation, based on large-scale fading (LSF) parameters, as the pre-processed input to the DNN. We train the DNN to refine the heuristic scheme, thereby providing higher SE, using only local information at each AP. Another distributed DNN that exploits side information assumed to be available at the central processing unit is designed for improved performance. Further, we develop a clustered DNN model where the LSF parameters of a small number of APs, forming a cluster within a relatively large network, are used to jointly approximate the power coefficients of the cluster.
翻译:本文审议了一个无细胞的大规模多投入多产出(MIMO)系统,该系统由大量地理分布的多产出点组成,通过连贯的联合传输为多个用户提供服务。对该系统的下行链路性能进行了评估,根据两个最优化的分权目标,即光谱效率(SE)最大化和比例公平性,对系统下行功能进行了最大比率和常规零推进预编码评估。我们提出了解决这些问题的迭代中央算法。我们的目标是减少计算复杂程度,并分配可扩展的解决方案。我们培训了一个深度神经网络,以大致接近整个网络的电力分配。我们不是培训我们的DNN(DNN)模拟实际优化程序,而是根据大规模法化参数,对系统下行进行超光速能力分配,作为对DNN(LSF)的预处理输入。我们培训DNN(DN)来改进超光速计划,从而提供更高的SE,只使用每个AP的当地信息。另一个分布式的DNNNN(DNN)网络,利用中央处理单位的假设的侧信息来改进业绩。此外,我们不是训练我们的DNNNNN(DNNN)模拟模拟模拟模拟模拟,而是根据大型的M(LSF)集成一个高频组的CM(CM)的CF)的群集集,我们开发了一个AF的CM(CM(CM)的CM)的CM(CF)的CM(CM)群域号)的群号的群号的群号。