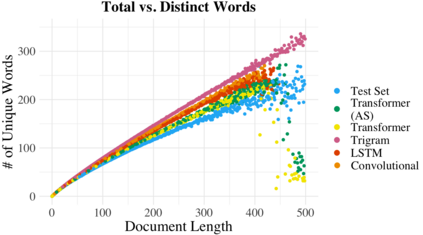
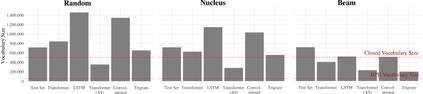
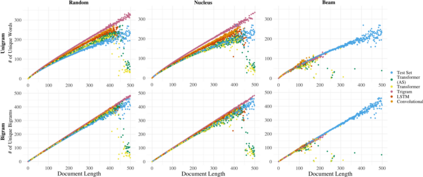
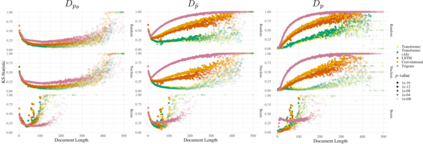
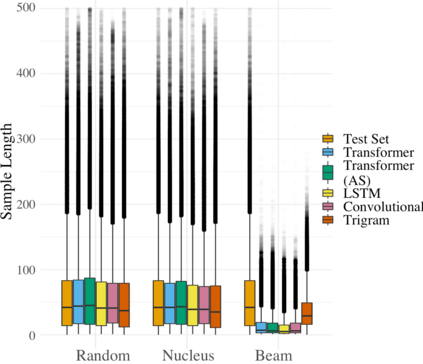
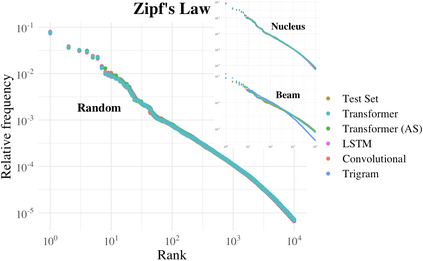
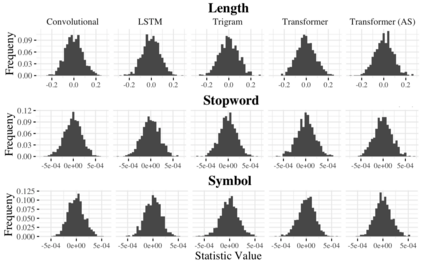
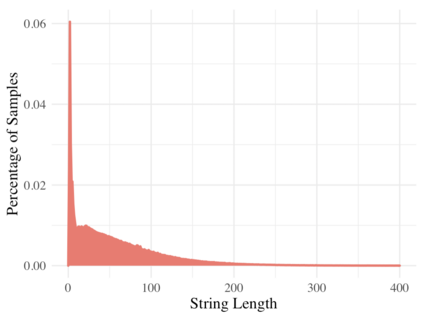
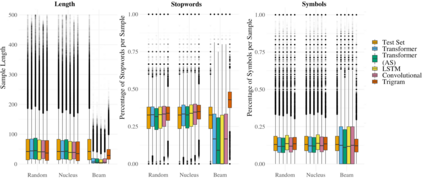
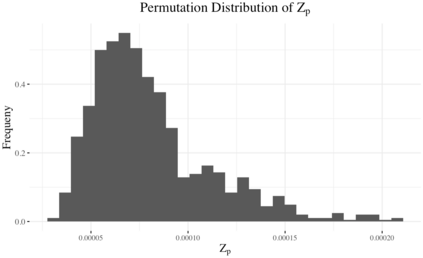
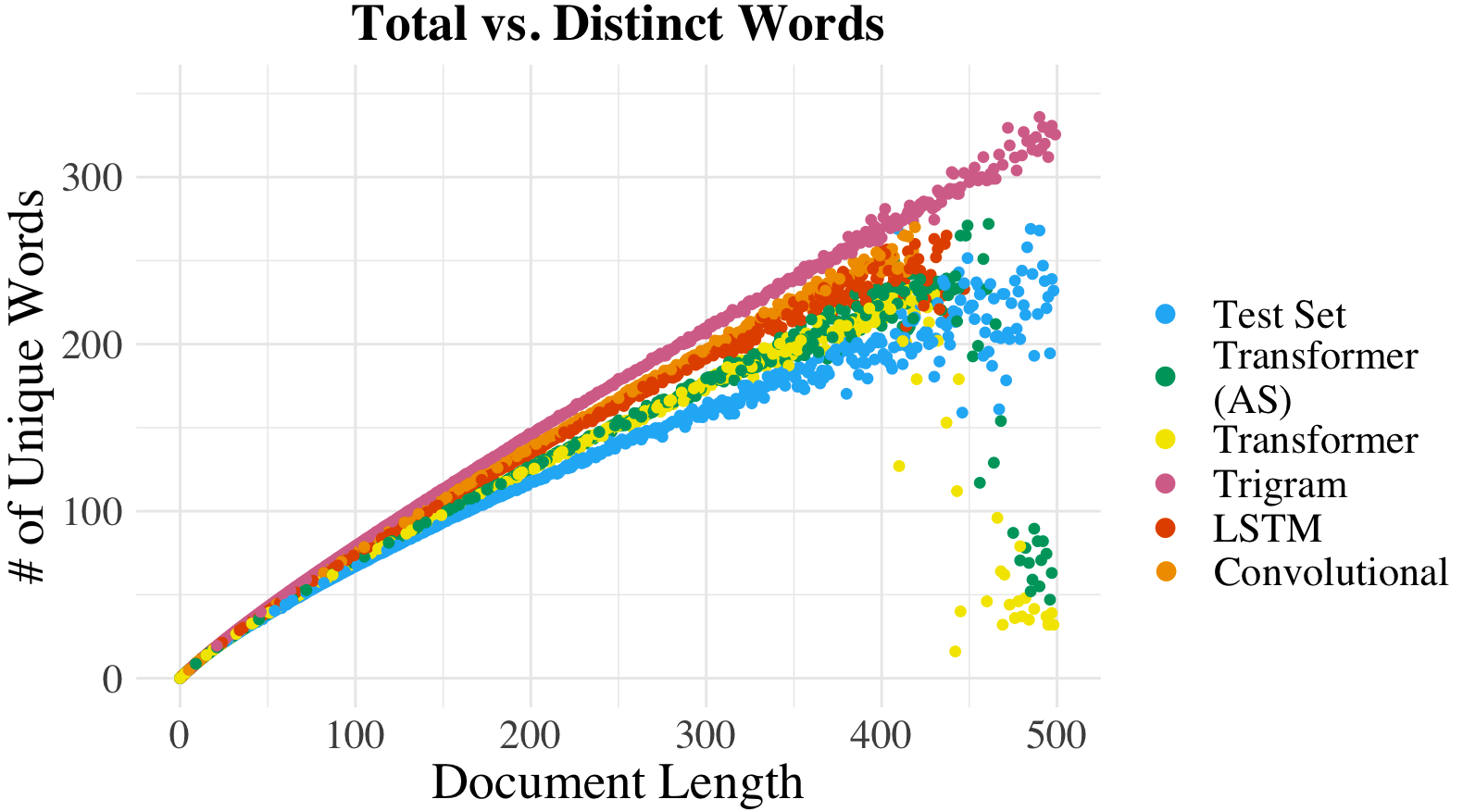
We propose an alternate approach to quantifying how well language models learn natural language: we ask how well they match the statistical tendencies of natural language. To answer this question, we analyze whether text generated from language models exhibits the statistical tendencies present in the human-generated text on which they were trained. We provide a framework--paired with significance tests--for evaluating the fit of language models to these trends. We find that neural language models appear to learn only a subset of the tendencies considered, but align much more closely with empirical trends than proposed theoretical distributions (when present). Further, the fit to different distributions is highly-dependent on both model architecture and generation strategy. As concrete examples, text generated under the nucleus sampling scheme adheres more closely to the type--token relationship of natural language than text produced using standard ancestral sampling; text from LSTMs reflects the natural language distributions over length, stopwords, and symbols surprisingly well.
翻译:我们提出了一种量化语言模式如何很好地学习自然语言的替代方法:我们问它们与自然语言统计趋势的匹配程度如何;为回答这个问题,我们分析语言模式产生的文本是否显示了他们接受培训的人类生成文本中存在的统计趋势;我们提供了一个框架,具有重大测试作用,用以评价语言模式是否适合这些趋势;我们发现神经语言模式似乎只学习了所考虑的几组趋势,但与经验趋势的吻合程度远高于(目前)拟议的理论分布。此外,适应不同分布的适宜性高度取决于模型结构和生成战略。具体的例子是,核心抽样方案产生的文本比使用标准祖先抽样制的文本更接近自然语言类型式式关系;LSTMS的文本反映了自然语言分布的长度、断字和符号令人惊讶地好。