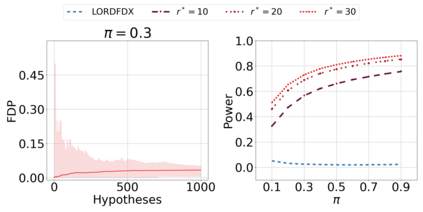
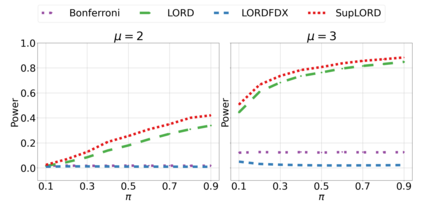
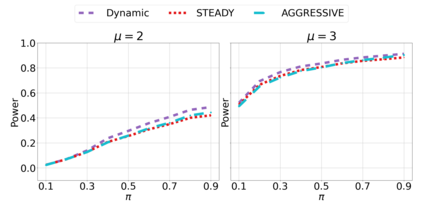
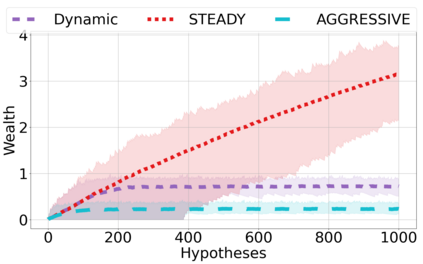
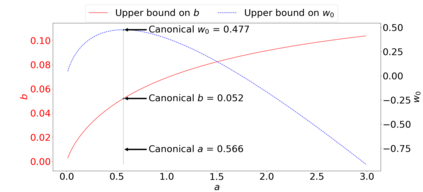
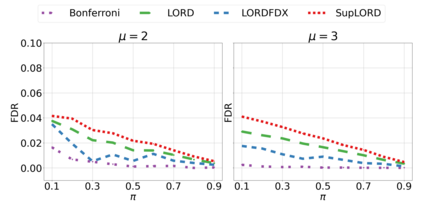
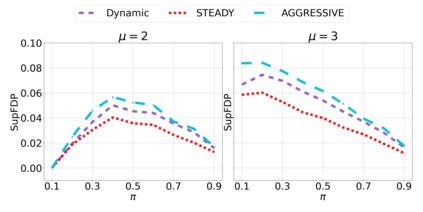
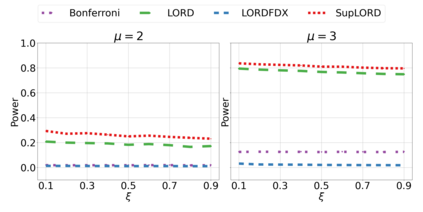
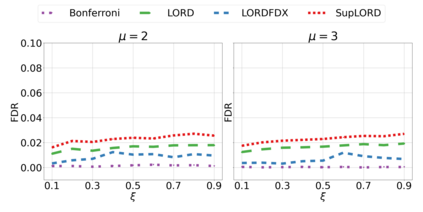
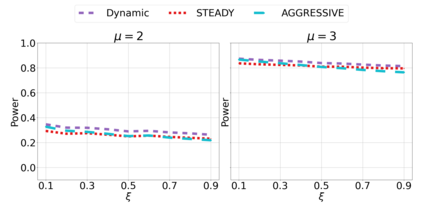
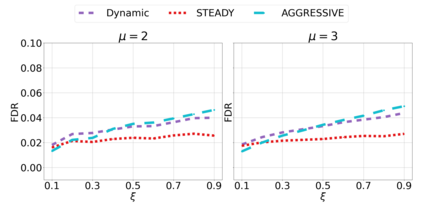
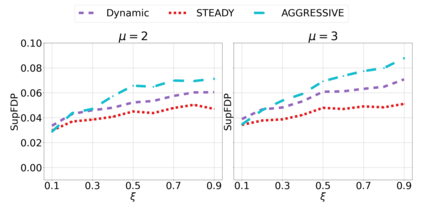
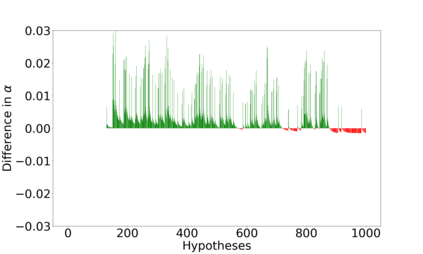
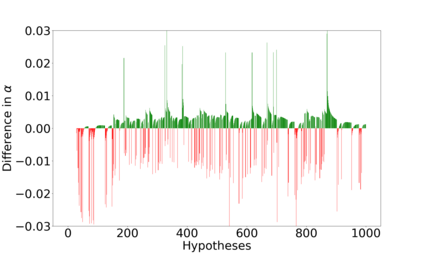
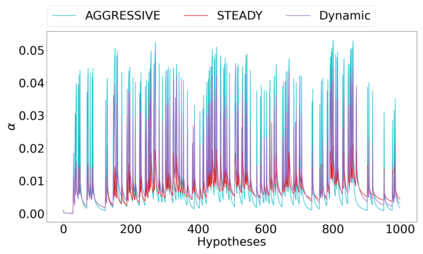
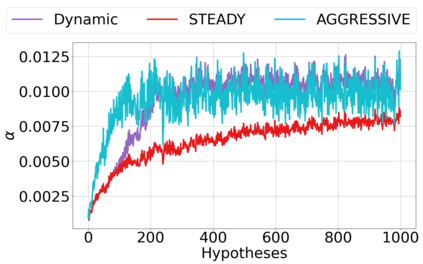
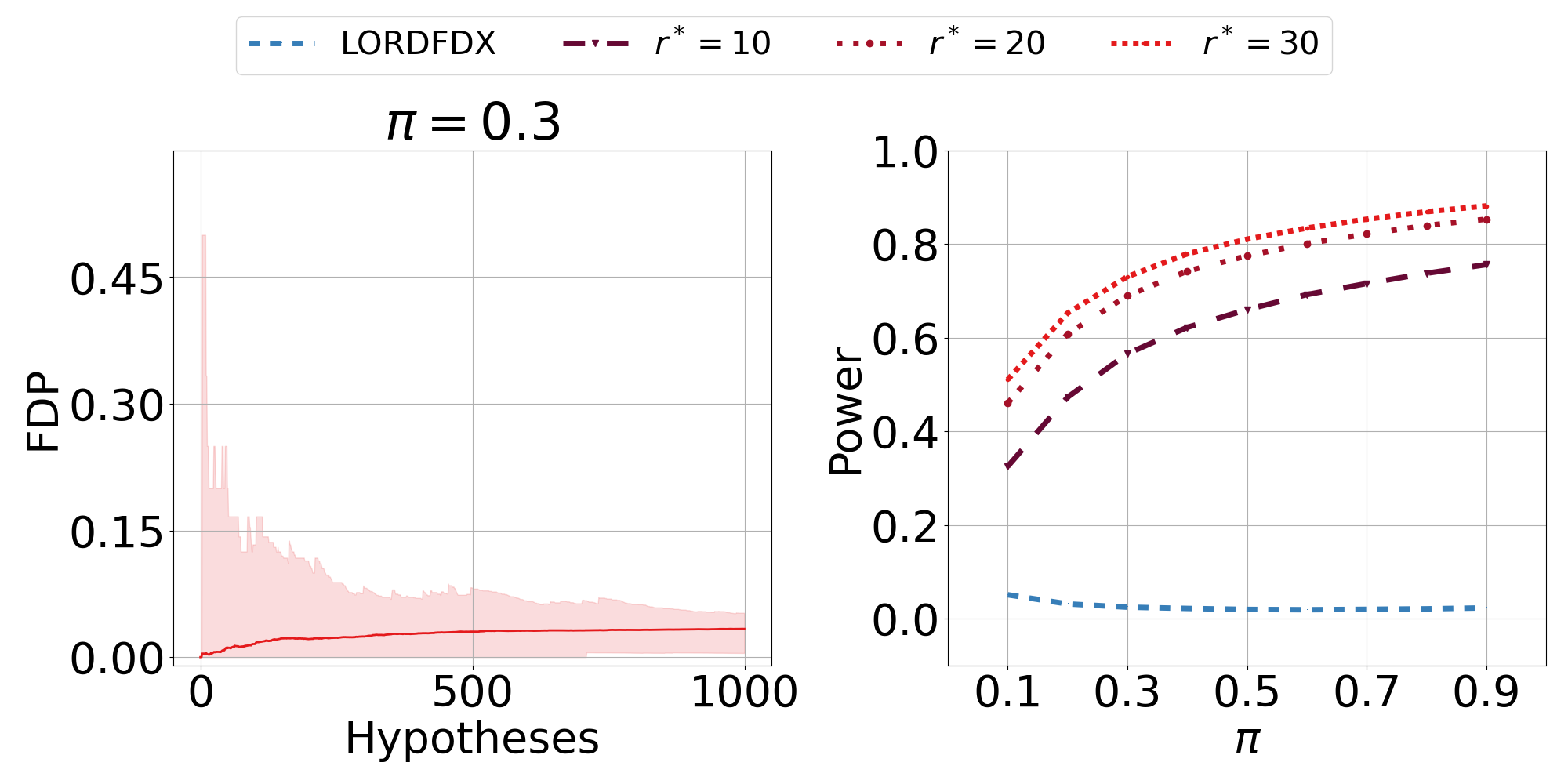
We derive new algorithms for online multiple testing that provably control false discovery exceedance (FDX) while achieving orders of magnitude more power than previous methods. This statistical advance is enabled by the development of new algorithmic ideas: earlier algorithms are more "static" while our new ones allow for the dynamical adjustment of testing levels based on the amount of wealth the algorithm has accumulated. We demonstrate that our algorithms achieve higher power in a variety of synthetic experiments. We also prove that SupLORD can provide error control for both FDR and FDX, and controls FDR at stopping times. Stopping times are particularly important as they permit the experimenter to end the experiment arbitrarily early while maintaining desired control of the FDR. SupLORD is the first non-trivial algorithm, to our knowledge, that can control FDR at stopping times in the online setting.
翻译:我们为在线多次测试推出新的算法,这些算法可以控制虚假的发现超量(FDX),同时取得比以往方法更大的能量级。这种统计进步是由新的算法理念的发展促成的:早期算法更“静态”而我们的新算法允许根据算法积累的财富量动态调整测试水平。我们证明我们的算法在各种合成实验中获得了更高的能量。我们还证明SupLORD可以为FDR和FDX提供错误控制,并在停止时控制FDR。 停止时间特别重要,因为它们允许实验者在保持对FDR的预期控制的同时尽早任意结束实验。 SupLORD是第一个在网络设置的停止时间控制FDR的非三轨算法,据我们所知,它是第一个能够控制FDR的在线设置中的非三角算法。