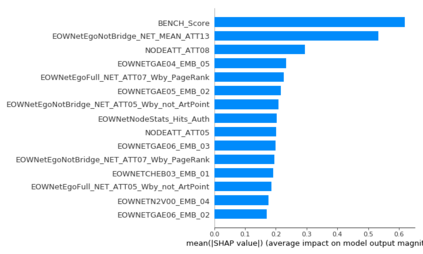
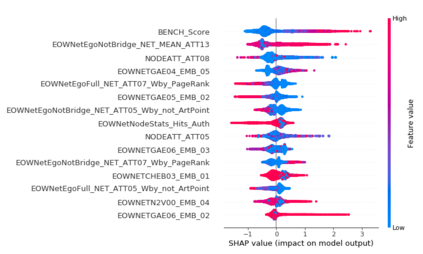
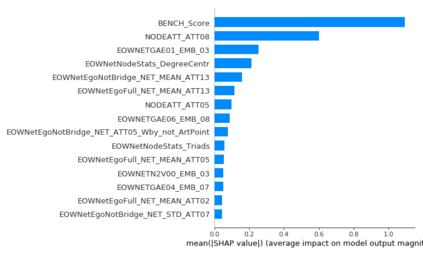
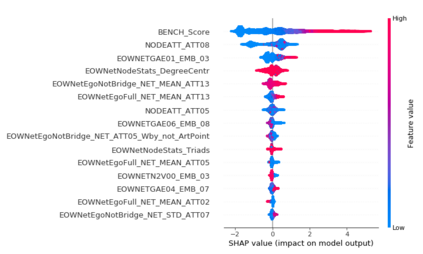
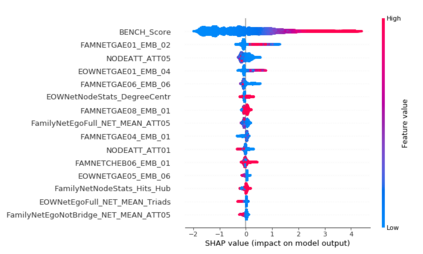
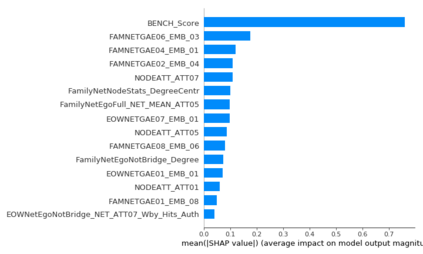
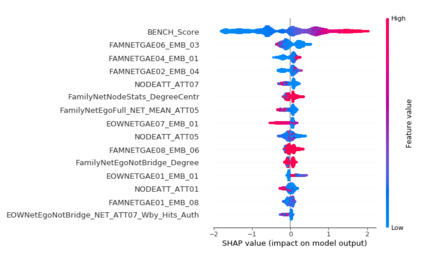
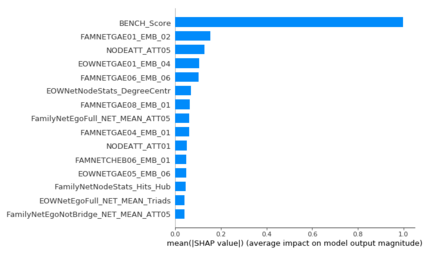
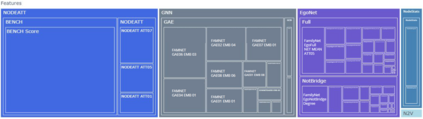
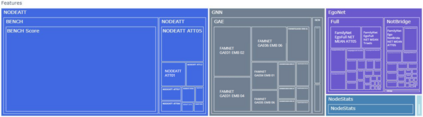
The thin-file borrowers are customers for whom a creditworthiness assessment is uncertain due to their lack of credit history; many researchers have used borrowers' relationships and interactions networks in the form of graphs as an alternative data source to address this. Incorporating network data is traditionally made by hand-crafted feature engineering, and lately, the graph neural network has emerged as an alternative, but it still does not improve over the traditional method's performance. Here we introduce a framework to improve credit scoring models by blending several Graph Representation Learning methods: feature engineering, graph embeddings, and graph neural networks. We stacked their outputs to produce a single score in this approach. We validated this framework using a unique multi-source dataset that characterizes the relationships and credit history for the entire population of a Latin American country, applying it to credit risk models, application, and behavior, targeting both individuals and companies. Our results show that the graph representation learning methods should be used as complements, and these should not be seen as self-sufficient methods as is currently done. In terms of AUC and KS, we enhance the statistical performance, outperforming traditional methods. In Corporate lending, where the gain is much higher, it confirms that evaluating an unbanked company cannot solely consider its features. The business ecosystem where these firms interact with their owners, suppliers, customers, and other companies provides novel knowledge that enables financial institutions to enhance their creditworthiness assessment. Our results let us know when and which group to use graph data and what effects on performance to expect. They also show the enormous value of graph data on the unbanked credit scoring problem, principally to help companies' banking.
翻译:低档借款人是客户,其信誉评估由于缺乏信用历史而不确定;许多研究人员使用图表形式的借款人关系和互动网络作为解决这一问题的替代数据源。整合网络数据传统上是由手工制作的特征工程制作的,最近,图形神经网络作为一种替代办法出现,但相对于传统方法的性能而言,它仍然没有得到改善。我们在这里引入了一个框架,通过混合几种图表代表学习方法来改进信用评分模式:特征工程、图形嵌入和图形神经网络。我们用图表形式堆叠了他们的产出,以得出这一方法的单一分数。我们用一个独特的多源数据集来验证这一框架,该数据集是拉丁美洲整个人口关系和信用史的特点,将这些数据应用于信用风险模型、应用和行为,针对个人和公司。我们的结果表明,图表显示学习方法应该作为补充,不应该像目前那样被视为自足的方法。从AUC和KS的角度看,我们提高了它们的统计业绩,超越了传统的方法。在企业借贷中,这些公司无法在银行业绩上展示自己的业绩,这些公司可以让银行的客户更深入地评估。