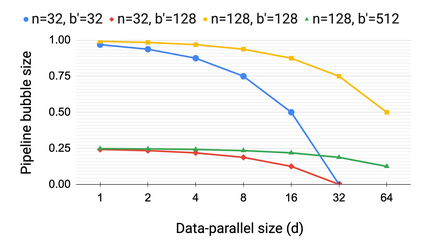
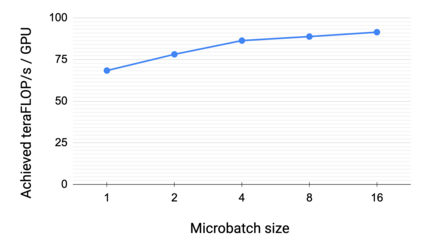
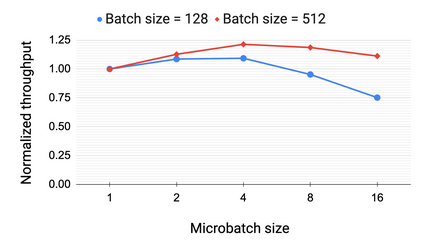
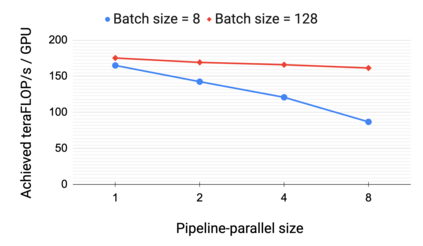
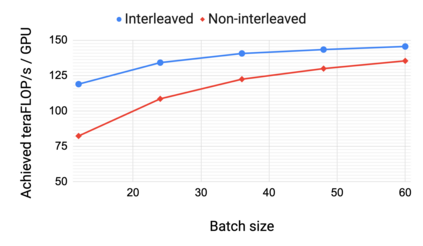
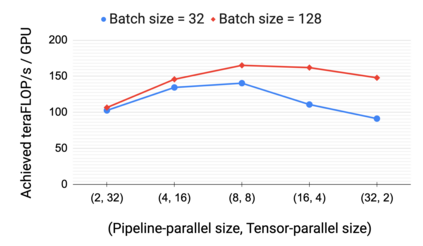
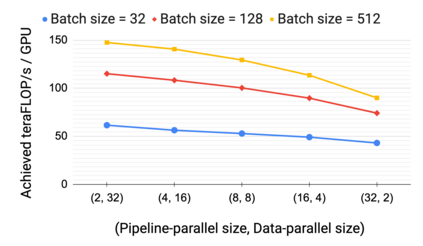
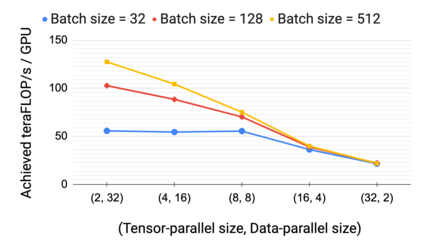
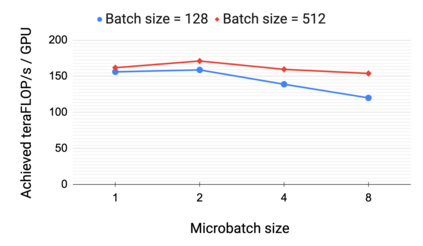
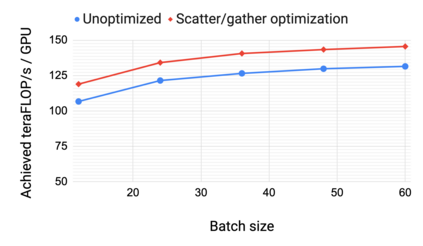
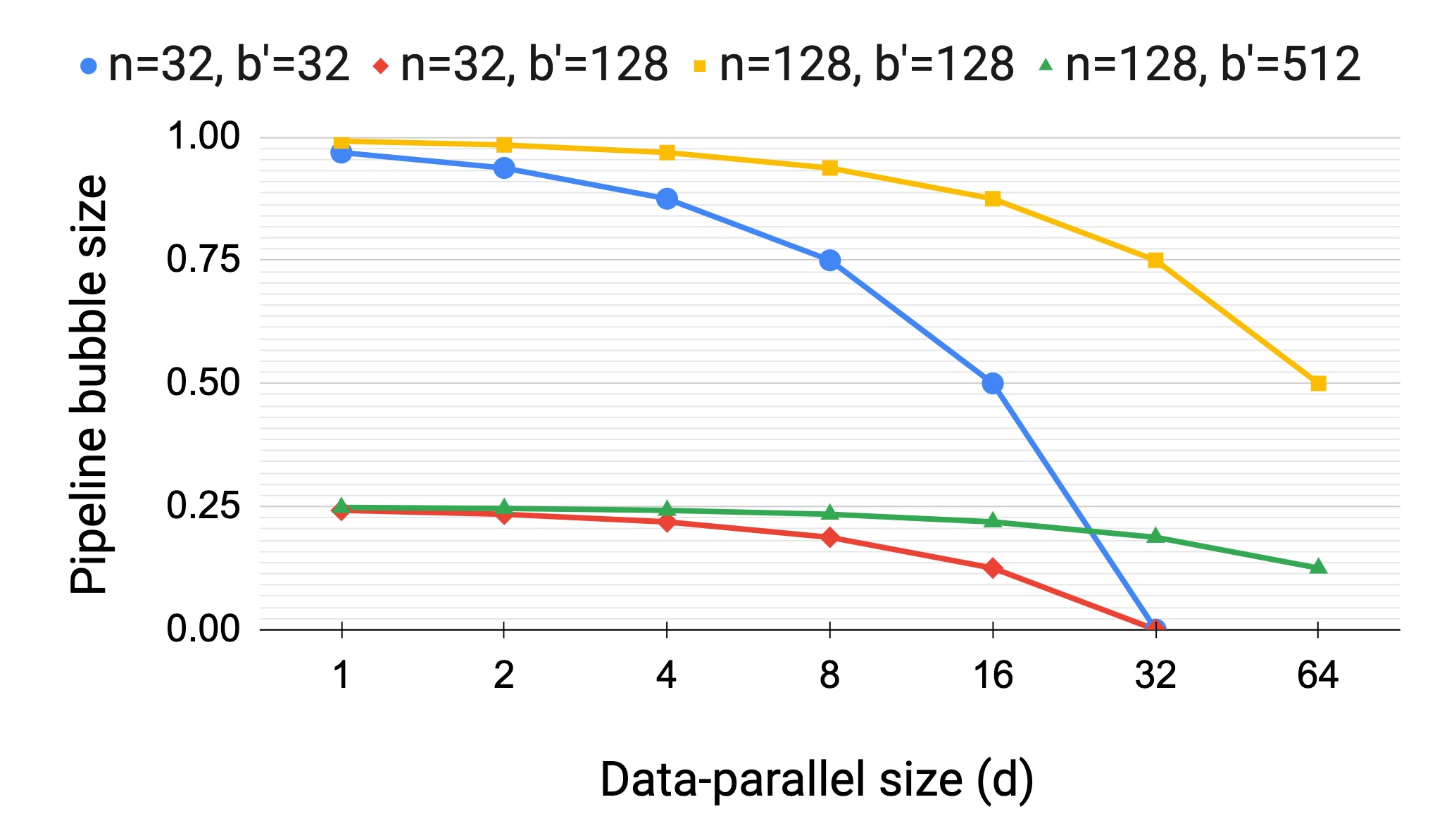
Large language models have led to state-of-the-art accuracies across a range of tasks. However, training these large models efficiently is challenging for two reasons: a) GPU memory capacity is limited, making it impossible to fit large models on a single GPU or even on a multi-GPU server; and b) the number of compute operations required to train these models can result in unrealistically long training times. New methods of model parallelism such as tensor and pipeline parallelism have been proposed to address these challenges. Unfortunately, naive usage leads to fundamental scaling issues at thousands of GPUs due to various reasons, e.g., expensive cross-node communication or idle periods waiting on other devices. In this work, we show how to compose different types of parallelism methods (tensor, pipeline, and data parallelism) to scale to thousands of GPUs, achieving a two-order-of-magnitude increase in the sizes of models we can efficiently train compared to existing systems. We survey techniques for pipeline parallelism and propose a novel interleaved pipeline parallelism schedule that can improve throughput by more than 10% with comparable memory footprint compared to previously-proposed approaches. We quantitatively study the trade-offs between tensor, pipeline, and data parallelism, and provide intuition as to how to configure distributed training of a large model. Our approach allows us to perform training iterations on a model with 1 trillion parameters at 502 petaFLOP/s on 3072 GPUs with achieved per-GPU throughput of 52% of peak; previous efforts to train similar-sized models achieve much lower throughput (36% of theoretical peak). Our code is open sourced at https://github.com/nvidia/megatron-lm.
翻译:大型语言模型导致了一系列任务中最先进的峰值。然而,由于以下两个原因,对这些大型模型的有效培训具有挑战性:(a) GPU记忆能力有限,无法将大型模型安装在单一的 GPU 上,甚至无法安装在多GPU服务器上;和(b) 培训这些模型所需的计算操作数量可能导致不现实的长期培训时间。提出了新的模型平行方法,如高压和平行模式,以应对这些挑战。不幸的是,由于各种原因,天真的使用导致数千个GPU出现根本性的升级问题,例如,昂贵的交叉节点通信或等待其他装置的闲置时间等。在这项工作中,我们展示了如何将不同类型的平行方法(电压、管道和数据平行)配置到数千个GPUP(电压、管道和数据平行操作),从而实现模型规模的2级增长,我们可以对现有系统进行高效培训。我们通过管道平行源调查并提出新的管道平行运行时间表,可以通过超过10 %的管道通信传输速度通信或相似的管道运行时间。我们之前的存储数据比以往的MDRFIA培训可以提供比数据。