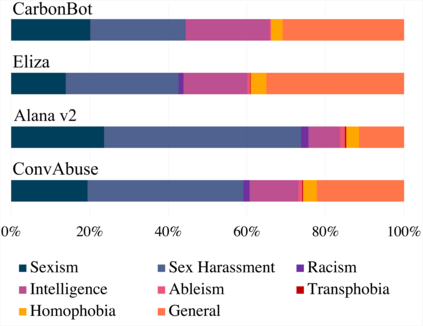
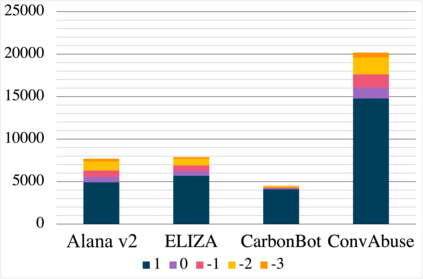
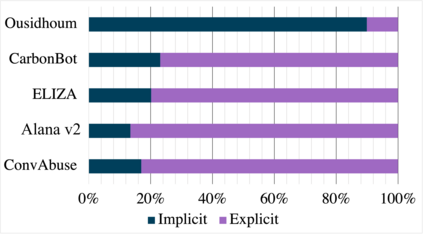
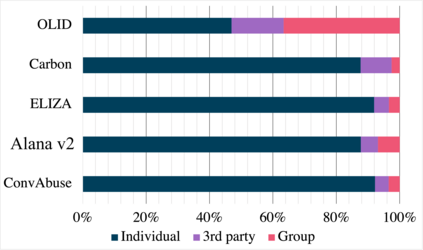
We present the first English corpus study on abusive language towards three conversational AI systems gathered "in the wild": an open-domain social bot, a rule-based chatbot, and a task-based system. To account for the complexity of the task, we take a more `nuanced' approach where our ConvAI dataset reflects fine-grained notions of abuse, as well as views from multiple expert annotators. We find that the distribution of abuse is vastly different compared to other commonly used datasets, with more sexually tinted aggression towards the virtual persona of these systems. Finally, we report results from bench-marking existing models against this data. Unsurprisingly, we find that there is substantial room for improvement with F1 scores below 90%.
翻译:我们对“野外”收集的三种对话性人工智能系统,即开放的社交机器人、有章可循的聊天机和基于任务的系统,提出了关于滥用语言的第一份英国文体研究。考虑到任务的复杂性,我们采取了更“细致”的方法,我们的ConvAI数据集反映了细微的虐待概念以及多位专家顾问的意见。我们发现,滥用的分布与其他常用数据集大不相同,对这些系统的虚拟人物的性侵犯性色化程度更高。最后,我们报告的是用现有模型标记这些数据的现有模型的结果。奇怪的是,我们发现有相当大的改进空间,F1分数低于90%。