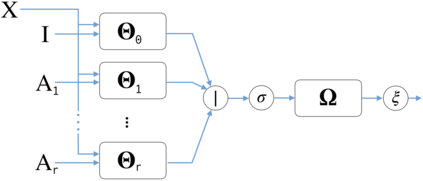
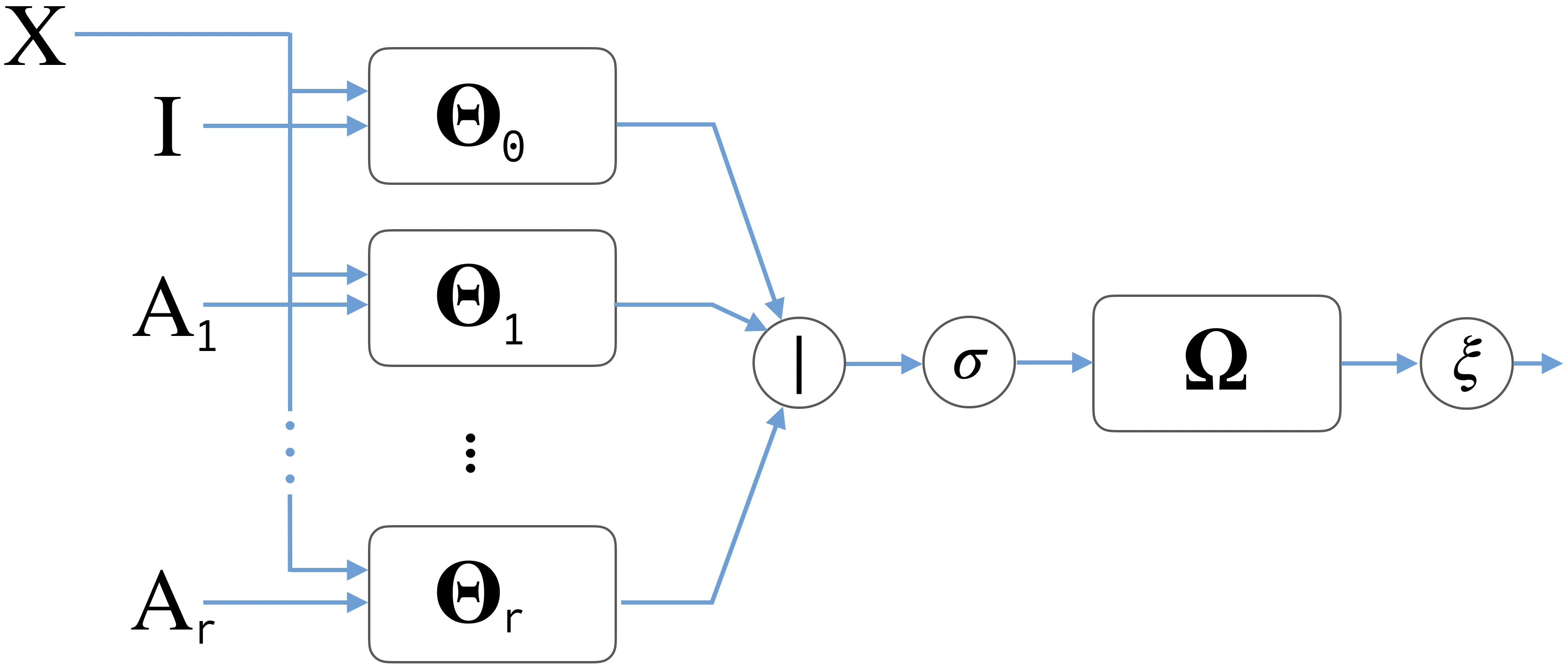
Graph representation learning has recently been applied to a broad spectrum of problems ranging from computer graphics and chemistry to high energy physics and social media. The popularity of graph neural networks has sparked interest, both in academia and in industry, in developing methods that scale to very large graphs such as Facebook or Twitter social networks. In most of these approaches, the computational cost is alleviated by a sampling strategy retaining a subset of node neighbors or subgraphs at training time. In this paper we propose a new, efficient and scalable graph deep learning architecture which sidesteps the need for graph sampling by using graph convolutional filters of different size that are amenable to efficient precomputation, allowing extremely fast training and inference. Our architecture allows using different local graph operators (e.g. motif-induced adjacency matrices or Personalized Page Rank diffusion matrix) to best suit the task at hand. We conduct extensive experimental evaluation on various open benchmarks and show that our approach is competitive with other state-of-the-art architectures, while requiring a fraction of the training and inference time.
翻译:最近,从计算机图形和化学到高能物理学和社交媒体等一系列广泛的问题都应用了图表代表学习方法,从计算机图形和化学到高能物理学和高能物理学,平面神经网络的普及在学术界和工业界都激发了人们的兴趣,他们开发了规模到Facebook或Twitter社交网络等非常大图表的方法。在大多数这些方法中,计算成本是通过在培训时保留一组节点邻居或子集成的抽样战略来减轻的。在本文中,我们提出了一个新的、高效和可扩缩的图表深层学习结构,它通过使用适合高效预估的平面图像过滤器来绕过图样取样的需要,允许极快的培训和推断。我们的结构允许使用不同的本地图形操作器(例如:motif引发的相近矩阵或个性化页级散列矩阵)来最好地适应手头的任务。我们对各种开放基准进行广泛的实验评估,并表明我们的方法与其他最先进的结构具有竞争力,同时需要一定的培训和推论时间。