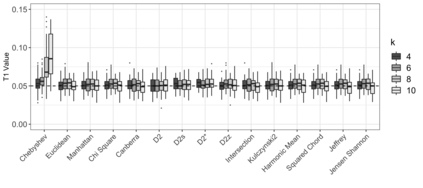
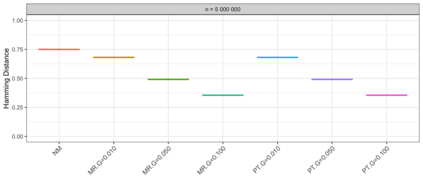
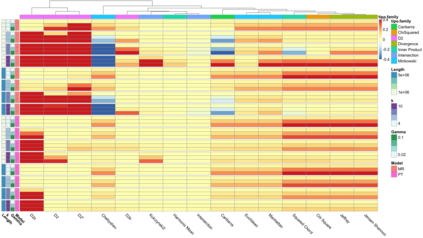
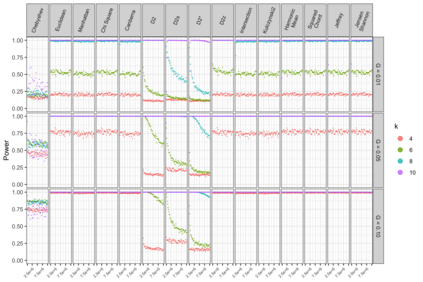
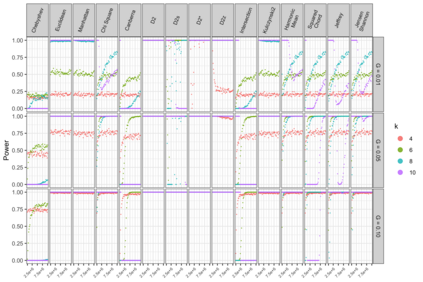
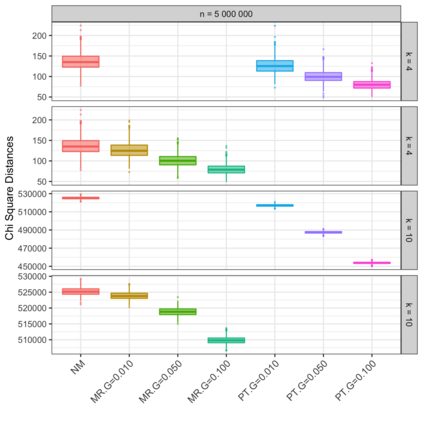
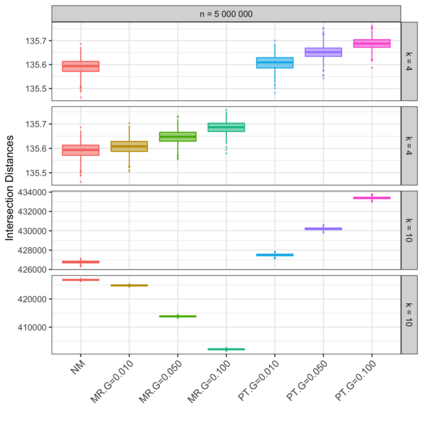
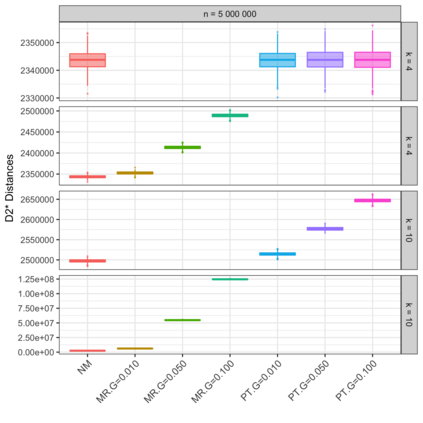
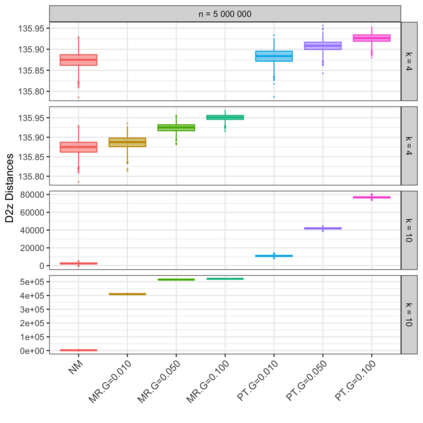
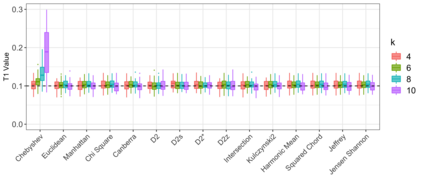
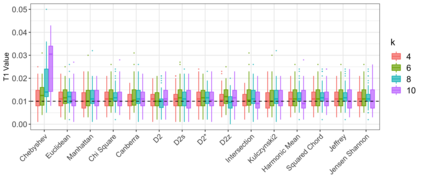
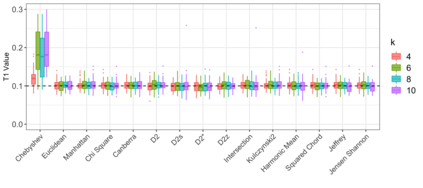
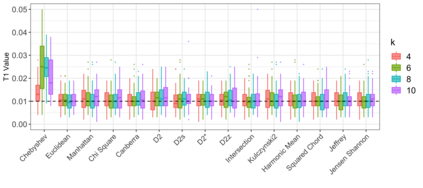
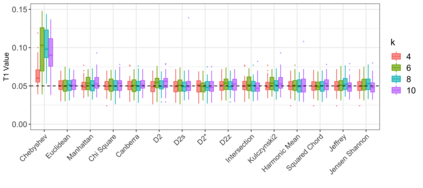
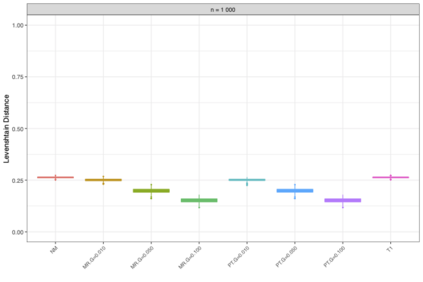
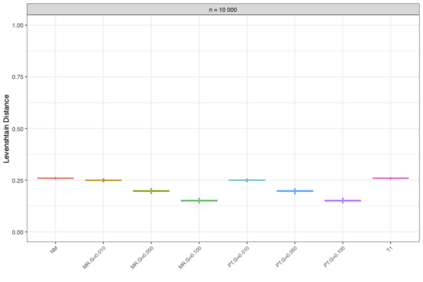
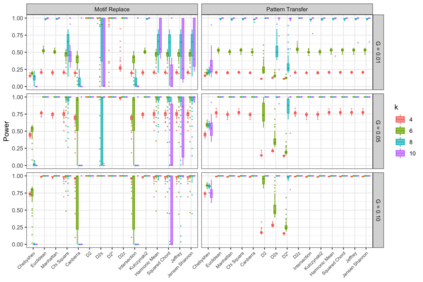
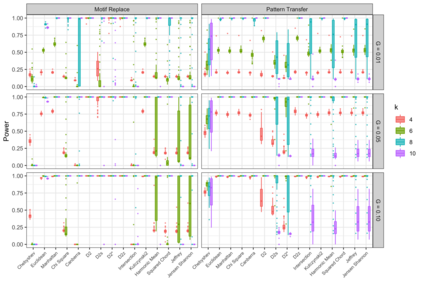
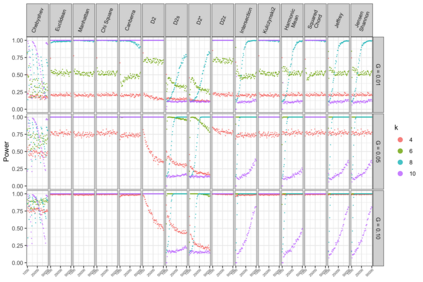
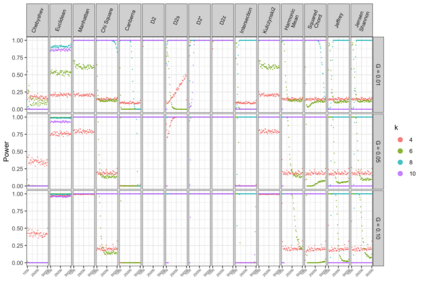
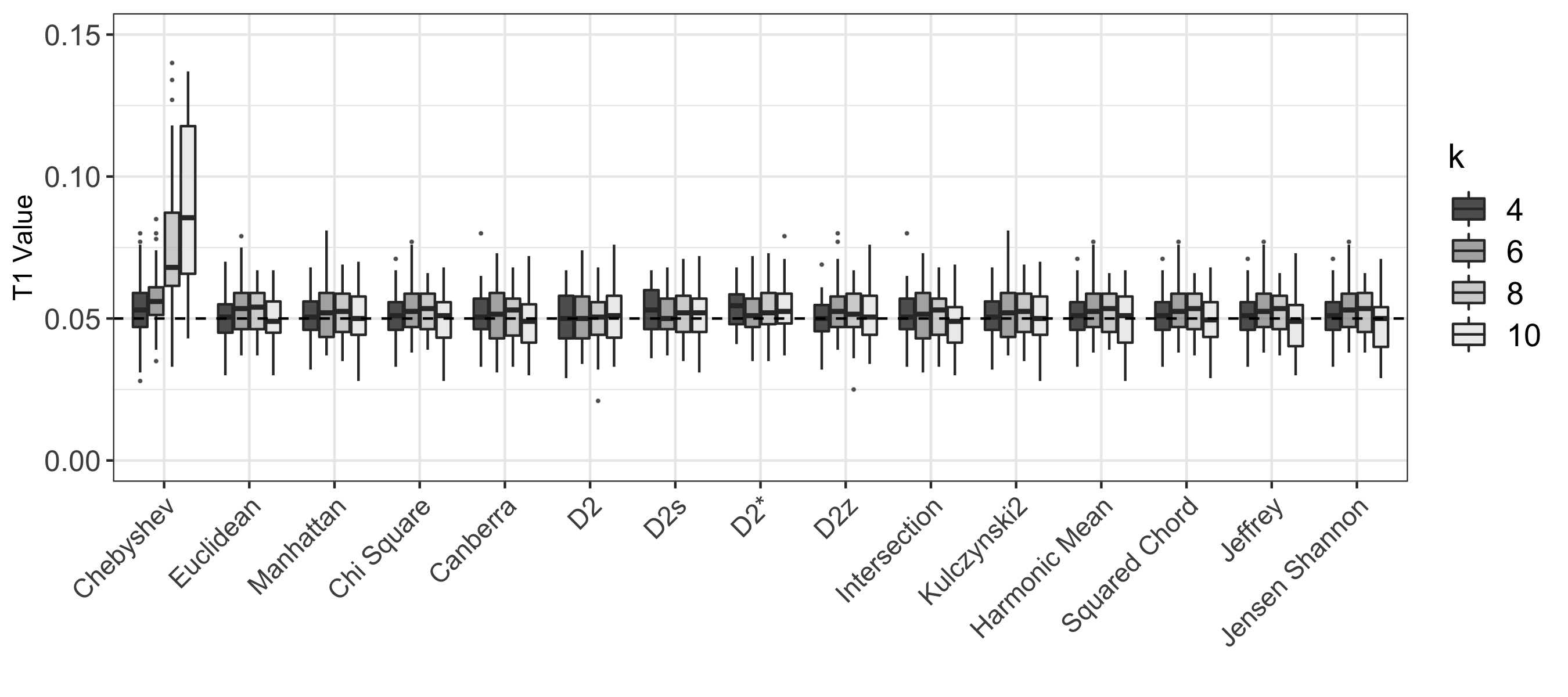
Motivation: Alignment-free (AF) distance/similarity functions are a key tool for sequence analysis. Experimental studies on real datasets abound and, to some extent, there are also studies regarding their control of false positive rate (Type I error). However, assessment of their power, i.e., their ability to identify true similarity, has been limited to some members of the D2 family by experimental studies on short sequences, not adequate for current applications, where sequence lengths may vary considerably. Such a State of the Art is methodologically problematic, since information regarding a key feature such as power is either missing or limited. Results: By concentrating on a representative set of word-frequency based AF functions, we perform the first coherent and uniform evaluation of the power, involving also Type I error for completeness. Two Alternative models of important genomic features (CIS Regulatory Modules and Horizontal Gene Transfer), a wide range of sequence lengths from a few thousand to millions, and different values of k have been used. As a result, we provide a characterization of those AF functions that is novel and informative. Indeed, we identify weak and strong points of each function considered, which may be used as a guide to choose one for analysis tasks. Remarkably, of the fifteen functions that we have considered, only four stand out, with small differences between small and short sequence length scenarios. Finally, in order to encourage the use of our methodology for validation of future AF functions, the Big Data platform supporting it is public.
翻译:动力:无协调(AF)距离/相似功能是进行序列分析的关键工具。关于真实数据集的实验研究是分析序列的关键工具。关于真实数据集的实验性研究很多,而且在某种程度上,还研究它们控制假正率(Type I 错误),但是,通过对短序列的实验研究,评估其权力,即它们确定真正相似性的能力,仅限于D2家族的一些成员,这些短序列的序列长度不足够,对当前应用程序的序列长度可能差异很大。这种艺术状态在方法上存在问题,因为有关权力等关键特征的信息要么缺失,要么有限。结果:通过集中对一组有代表性的以字频为基础的AF函数进行实验性研究,我们首次对权力进行了一致和统一的评估,其中也包括类型I对完整性的错误。两种重要的基因组合特征的替代模型(CIS管理模块和水平基因传输),其序列长度范围很广,从几千到数百万不等,而且使用k值也各不相同。结果,我们为这些功能的定性提供了新颖和信息。结果:我们通过集中的一组基于基于基于字频频频谱的功能,我们选择了每个功能的薄弱和强点,最后选择了每个功能的模型的细度分析。我们所考虑的细图的细图的细数。我们所考虑的大小。