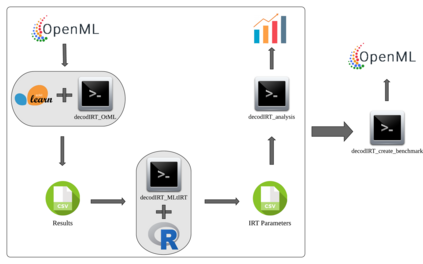
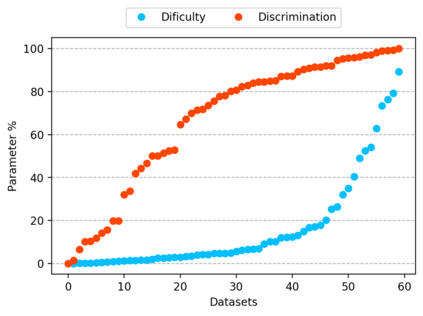
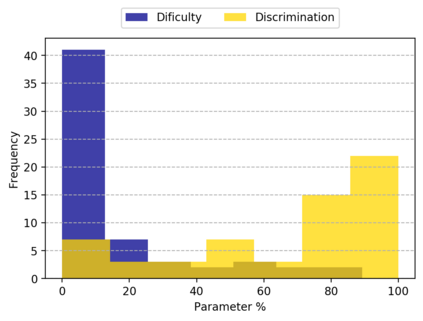
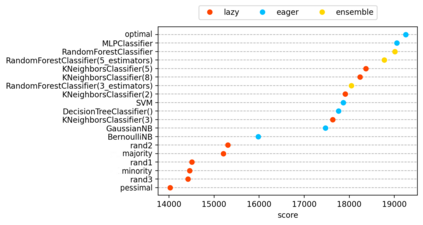
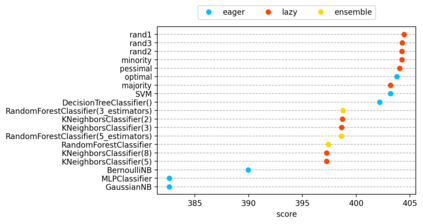
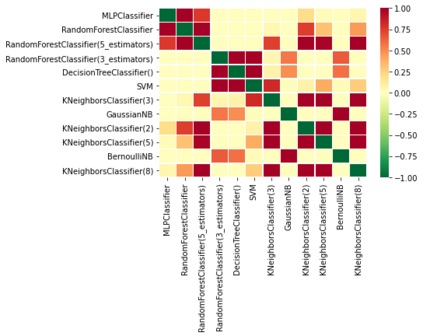
The classification experiments covered by machine learning (ML) are composed by two important parts: the data and the algorithm. As they are a fundamental part of the problem, both must be considered when evaluating a model's performance against a benchmark. The best classifiers need robust benchmarks to be properly evaluated. For this, gold standard benchmarks such as OpenML-CC18 are used. However, data complexity is commonly not considered along with the model during a performance evaluation. Recent studies employ Item Response Theory (IRT) as a new approach to evaluating datasets and algorithms, capable of evaluating both simultaneously. This work presents a new evaluation methodology based on IRT and Glicko-2, jointly with the decodIRT tool developed to guide the estimation of IRT in ML. It explores the IRT as a tool to evaluate the OpenML-CC18 benchmark for its algorithmic evaluation capability and checks if there is a subset of datasets more efficient than the original benchmark. Several classifiers, from classics to ensemble, are also evaluated using the IRT models. The Glicko-2 rating system was applied together with IRT to summarize the innate ability and classifiers performance. It was noted that not all OpenML-CC18 datasets are really useful for evaluating algorithms, where only 10% were rated as being really difficult. Furthermore, it was verified the existence of a more efficient subset containing only 50% of the original size. While Randon Forest was singled out as the algorithm with the best innate ability.
翻译:机器学习(ML)所涵盖的分类实验由两个重要部分组成: 数据和算法。 由于它们是问题的一个基本部分, 两者都是问题的基本部分, 在根据基准评估模型的性能时都必须加以考虑。 最佳分类者需要严格的基准来进行适当的评估。 为此, 使用了OpenML- CC18等金标准基准。 然而, 在业绩评估期间, 通常没有将数据的复杂性与模型一起考虑。 最近的研究使用项目反应理论( IRT) 作为评价数据集和算法的新方法, 能够同时评价两者。 这项工作在根据IMT和Gliko-2 评估模型来评估模型的性能时, 都要考虑到新的评价方法。 Gliko-2 评级系统与 IRT 一起应用了一个新的评价方法, 并结合开发了 DecodIRT 工具来指导对 MRT 的性能进行估算。 它探索了IML- 标准是用来评价其算法能力的一种工具, 如果有一个比原基准更有效率的子集。 它只是一些从经典到混合的分类, 。 它与Ilodio - liketal labal rest daldal be be ex ex ex ex real ex ex ex ex ex ex ex ex ex ex ex ex ex ex exlicuilutal ex ex ex ex ex ex ex ex ex ex ex ex ex ex ex lautus ex ex ex ex ex ex ex exitalitalital ex ex ex ex ex ex lautus ex ex ex laus lauts lauts lautus labildis labildildus ex ex ex ex ex ex ex ex labild. labild.