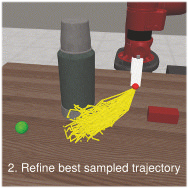
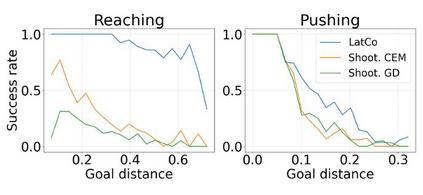
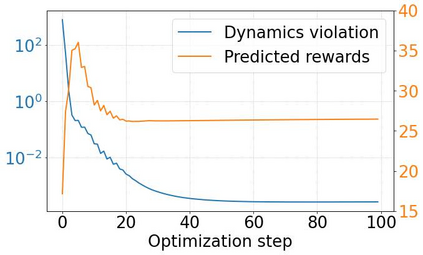
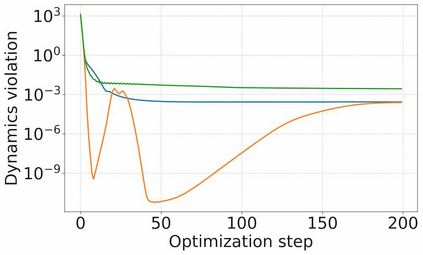
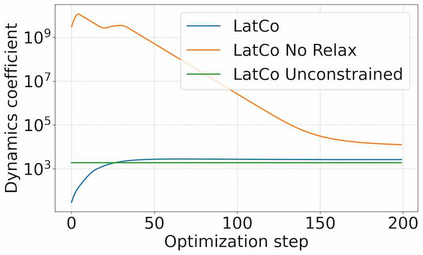
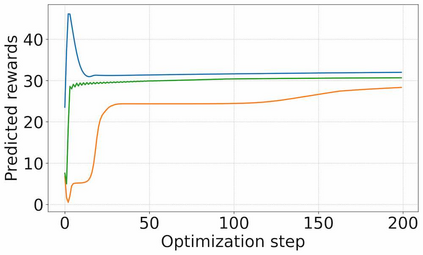
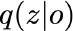The ability to plan into the future while utilizing only raw high-dimensional observations, such as images, can provide autonomous agents with broad capabilities. Visual model-based reinforcement learning (RL) methods that plan future actions directly have shown impressive results on tasks that require only short-horizon reasoning, however, these methods struggle on temporally extended tasks. We argue that it is easier to solve long-horizon tasks by planning sequences of states rather than just actions, as the effects of actions greatly compound over time and are harder to optimize. To achieve this, we draw on the idea of collocation, which has shown good results on long-horizon tasks in optimal control literature, and adapt it to the image-based setting by utilizing learned latent state space models. The resulting latent collocation method (LatCo) optimizes trajectories of latent states, which improves over previously proposed shooting methods for visual model-based RL on tasks with sparse rewards and long-term goals. Videos and code at https://orybkin.github.io/latco/.
翻译:仅利用图像等原始高维观测,规划未来的能力,但只能利用图像等原始高维观测,才能为自主代理提供广泛的能力。直接规划未来行动的视觉模型强化学习方法在只要求短光度推理的任务上显示了令人印象深刻的成果,然而,这些方法在时间推移的任务上挣扎。我们争辩说,通过规划国家序列而不是仅仅行动来解决长期横向任务比较容易,因为行动的影响随着时间的推移大大地复杂化,而且更难优化。为了实现这一点,我们借鉴了合用同一点的理念,该理念在最佳控制文献的长期横向任务上展示了良好的效果,并且通过利用所学的潜伏状态空间模型,使它适应基于图像的设置。由此产生的潜在合用法(LatCo)优化了潜伏状态的轨迹,从而改进了先前提议的以视觉模型为基础的RL关于稀薄奖励和长期目标的任务的射击方法。视频和代码见https://orybkin.github.io/latco/。