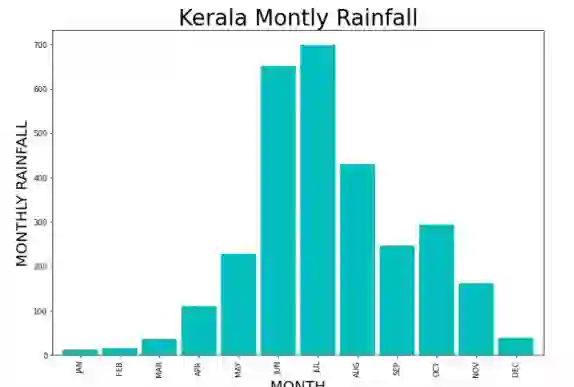
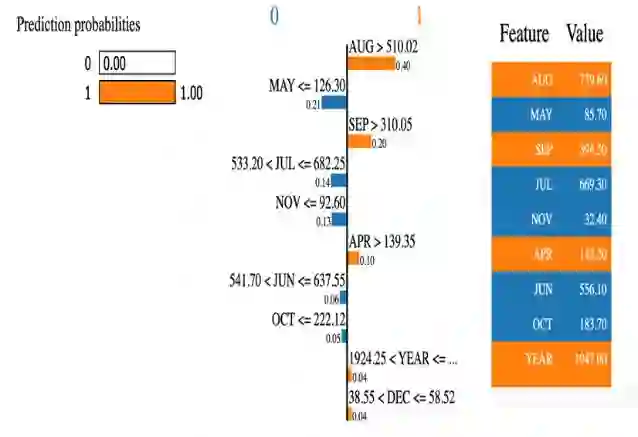
This paper presents flood prediction models for the state of Kerala in India by analyzing the monthly rainfall data and applying machine learning algorithms including Logistic Regression, K-Nearest Neighbors, Decision Trees, Random Forests, and Support Vector Machine. Although these models have shown high accuracy prediction of the occurrence of flood in a particular year, they do not quantitatively and qualitatively explain the prediction decision. This paper shows how the background features are learned that contributed to the prediction decision and further extended to explain the inner workings with the development of explainable artificial intelligence modules. The obtained results have confirmed the validity of the findings uncovered by the explainer modules basing on the historical flood monthly rainfall data in Kerala.
翻译:本文件介绍了印度喀拉拉邦的洪水预测模型,分析了月降雨量数据,并采用了机算方法,包括后勤回归、K-Nearest邻居、决策树、随机森林和辅助矢量机。虽然这些模型显示对特定年份发生洪水的准确性预测很高,但没有从数量和质量上解释预测决定。本文说明了如何了解有助于预测决定的背景特征,并进一步扩展,以解释开发可解释的人工智能模块的内部工作。获得的结果证实了解释器模块根据喀拉拉历史洪水月降雨数据所发现的调查结果的有效性。