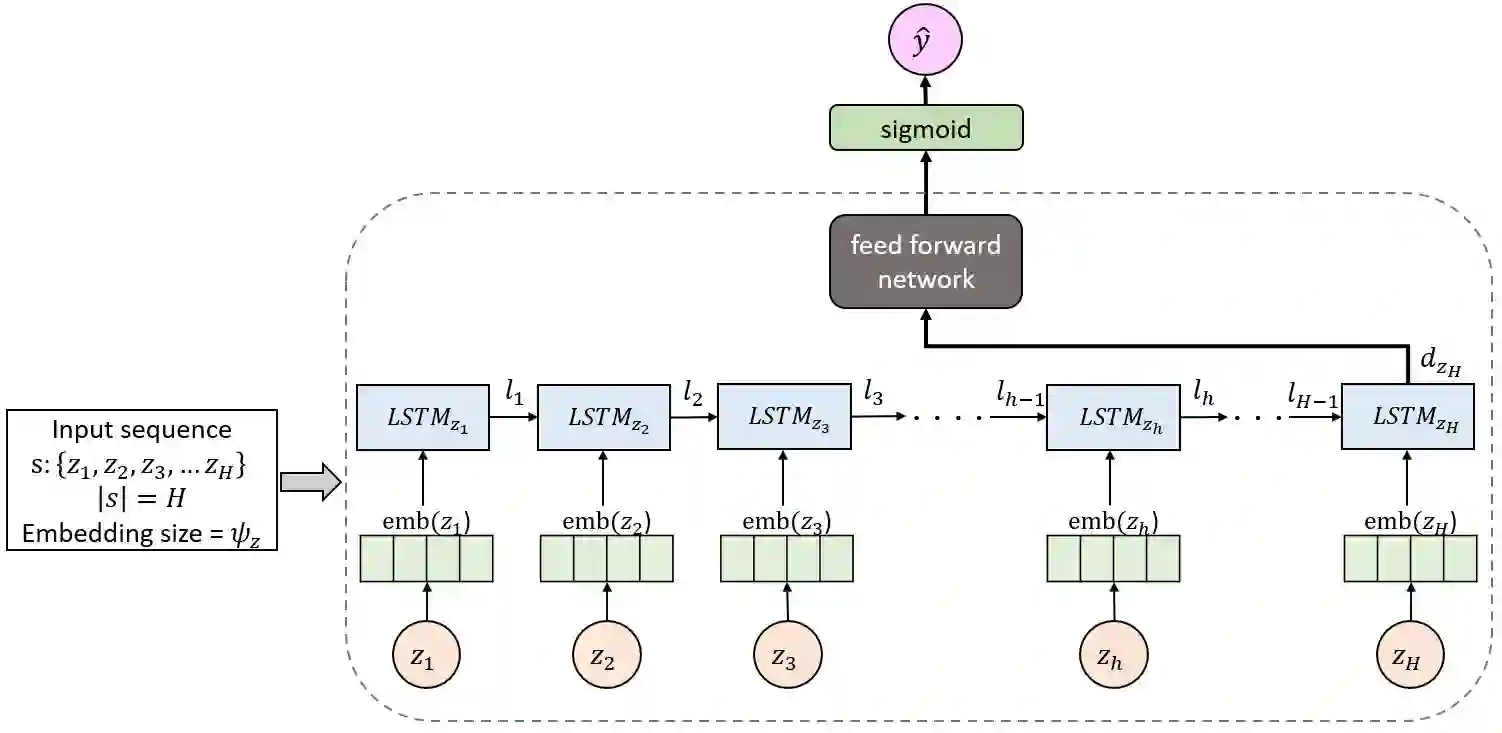
As various city agencies and mobility operators navigate toward innovative mobility solutions, there is a need for strategic flexibility in well-timed investment decisions in the design and timing of mobility service regions, i.e. cast as "real options" (RO). This problem becomes increasingly challenging with multiple interacting RO in such investments. We propose a scalable machine learning based RO framework for multi-period sequential service region design & timing problem for mobility-on-demand services, framed as a Markov decision process with non-stationary stochastic variables. A value function approximation policy from literature uses multi-option least squares Monte Carlo simulation to get a policy value for a set of interdependent investment decisions as deferral options (CR policy). The goal is to determine the optimal selection and timing of a set of zones to include in a service region. However, prior work required explicit enumeration of all possible sequences of investments. To address the combinatorial complexity of such enumeration, we propose a new variant "deep" RO policy using an efficient recurrent neural network (RNN) based ML method (CR-RNN policy) to sample sequences to forego the need for enumeration, making network design & timing policy tractable for large scale implementation. Experiments on multiple service region scenarios in New York City (NYC) shows the proposed policy substantially reduces the overall computational cost (time reduction for RO evaluation of > 90% of total investment sequences is achieved), with zero to near-zero gap compared to the benchmark. A case study of sequential service region design for expansion of MoD services in Brooklyn, NYC show that using the CR-RNN policy to determine optimal RO investment strategy yields a similar performance (0.5% within CR policy value) with significantly reduced computation time (about 5.4 times faster).
翻译:随着各城市机构和流动运营商走向创新的流动性解决方案,在流动服务区域设计和时间安排方面,需要具有战略灵活性,即作为“现实选项”(RO)在设计和时间安排良好的投资决策中,在流动服务区域设计和时间安排方面,需要有战略灵活性。在这种投资区域中,随着多周期连续服务区域设计和时间安排问题,我们提出一个可扩缩的机器学习RO框架,用于多周期连续服务区域设计和时间安排问题,这个框架是带有非静止随机变量的Markov决策程序。文献的扩展政策使用多选项最小方的蒙特卡洛模拟,以获得一套相互依存的投资决策的政策价值,作为延迟选项(CRR政策)。目标是确定一组区域的最佳选择和时间安排,以便纳入服务区域。然而,我们建议采用新的变式“深度”RO政策,使用高效的经常性网络(RC-NNN) 方法(C-NNP政策) 来抽样顺序,以接近直线投资选择一系列的投资决策值(MRC),让网络设计整个投资区域预算周期的计算大幅降低成本。