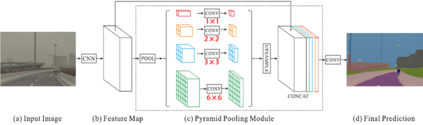
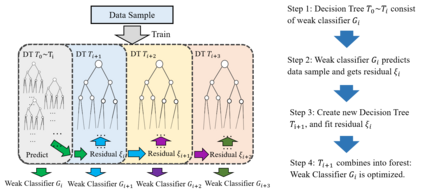
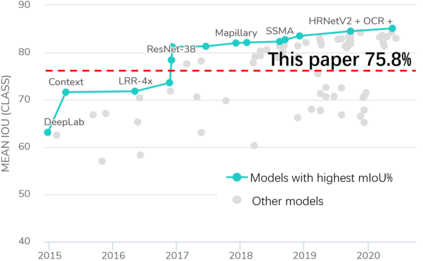
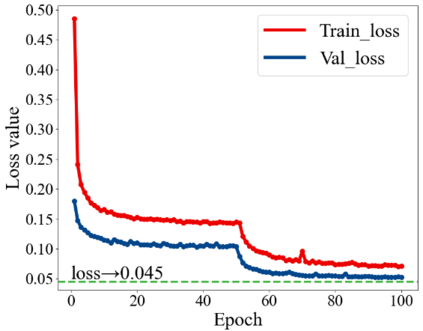
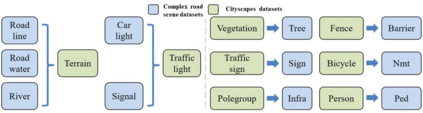
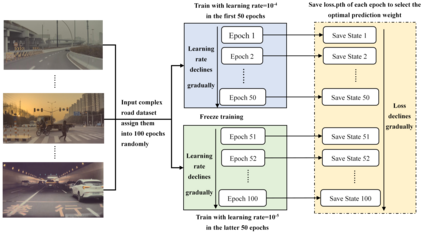
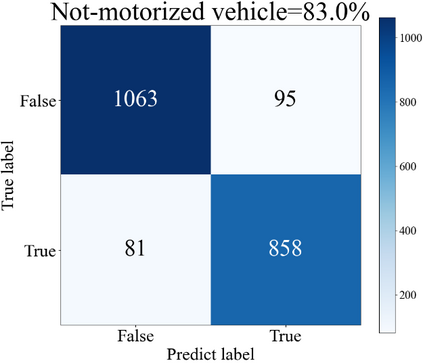
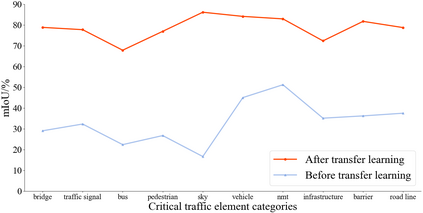
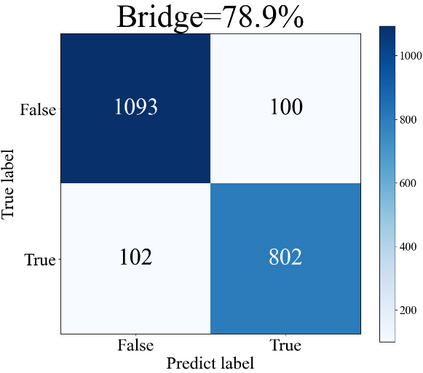
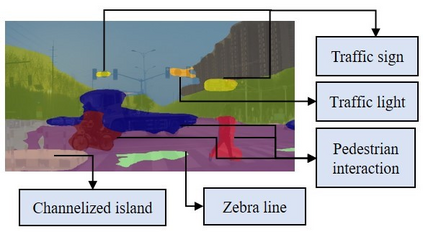
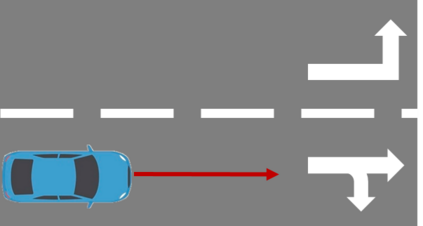
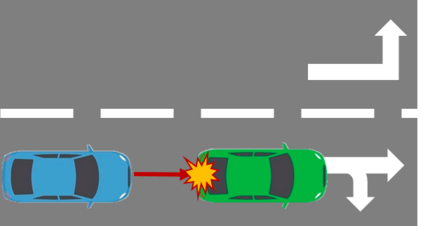
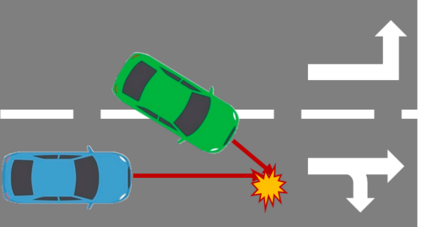
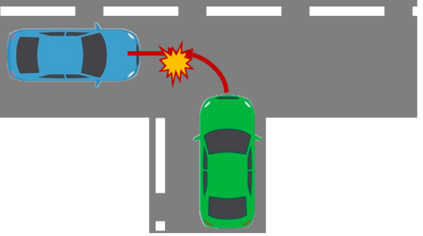
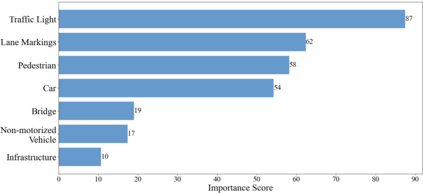
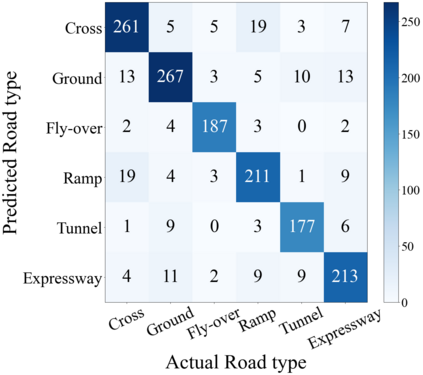
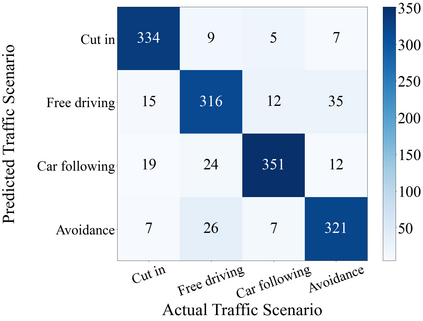
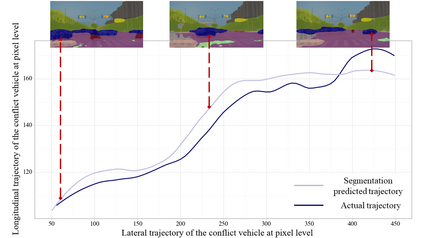
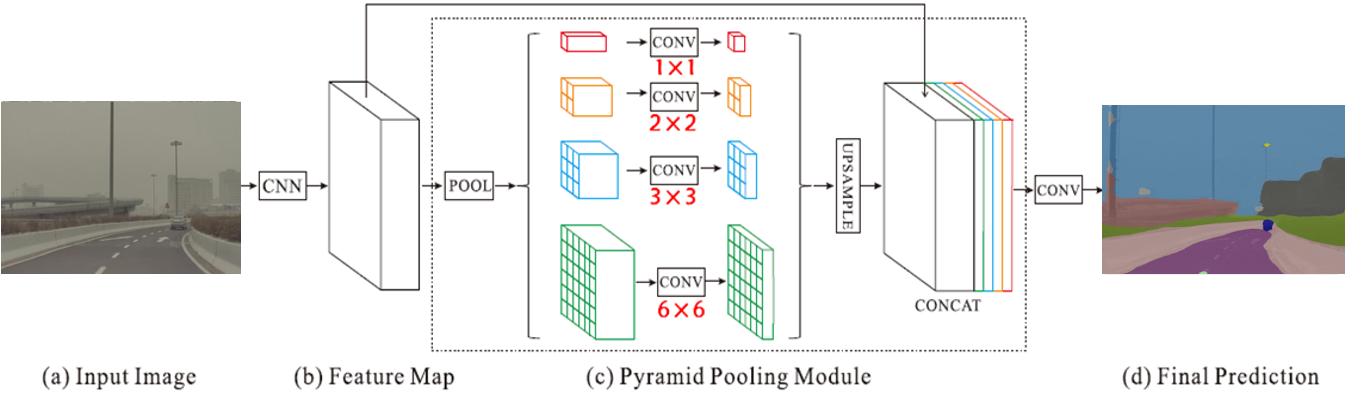
The complex driving environment brings great challenges to the visual perception of autonomous vehicles. It's essential to extract clear and explainable information from the complex road and traffic scenarios and offer clues to decision and control. However, the previous scene explanation had been implemented as a separate model. The black box model makes it difficult to interpret the driving environment. It cannot detect comprehensive textual information and requires a high computational load and time consumption. Thus, this study proposed a comprehensive and efficient textual explanation model. From 336k video frames of the driving environment, critical images of complex road and traffic scenarios were selected into a dataset. Through transfer learning, this study established an accurate and efficient segmentation model to obtain the critical traffic elements in the environment. Based on the XGBoost algorithm, a comprehensive model was developed. The model provided textual information about states of traffic elements, the motion of conflict objects, and scenario complexity. The approach was verified on the real-world road. It improved the perception accuracy of critical traffic elements to 78.8%. The time consumption reached 13 minutes for each epoch, which was 11.5 times more efficient than the pre-trained network. The textual information analyzed from the model was also accordant with reality. The findings offer clear and explainable information about the complex driving environment, which lays a foundation for subsequent decision and control. It can improve the visual perception ability and enrich the prior knowledge and judgments of complex traffic situations.
翻译:复杂的驾驶环境给对自主车辆的视觉认识带来了巨大的挑战。 从复杂的公路和交通情况中提取清晰和可解释的信息,并为决策和控制提供线索至关重要。 但是,以前的现场解释已经作为一个单独的模型实施。 黑盒模型使得很难解释驾驶环境。 它无法检测全面的文本信息,需要很高的计算负荷和时间消耗量。 因此, 这项研究提出了一个全面和高效的文本解释模型。 从336k的驾驶环境视频框中, 复杂的公路和交通情况的关键图像被选入数据集。 通过传输学习, 这项研究建立了一个准确和高效的分解模型, 以获取环境中的关键交通要素。 基于 XGBoost 算法, 开发了一个全面的模型。 模型提供了有关交通要素状况、 冲突物体的动态和情景复杂性的文本信息。 该模型将关键交通要素的感知度提高到78.8%。 每条路的时段消费达到13分钟, 比预先培训的网络效率高11.5倍。 文本信息能够解释后期的准确性判断和后期判断基础。 该模型提供了清晰的精确性分析, 并分析后视环境的精确性基础。 该模型可以提供精确性分析, 并解释后期判断和后视环境的精确性基础。 能够提供精确性判断。