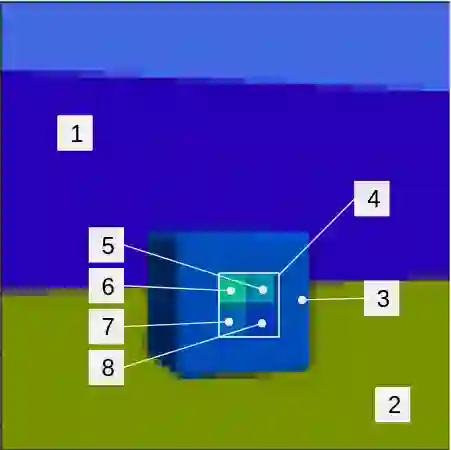
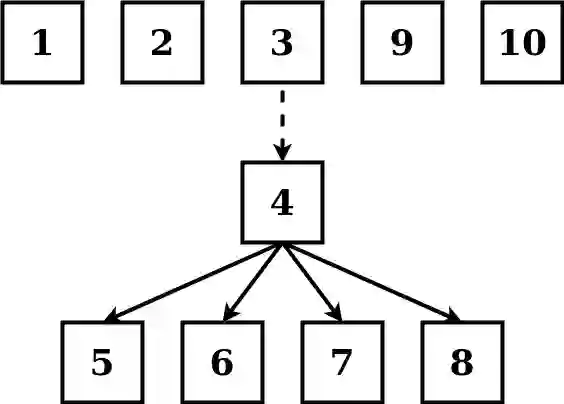
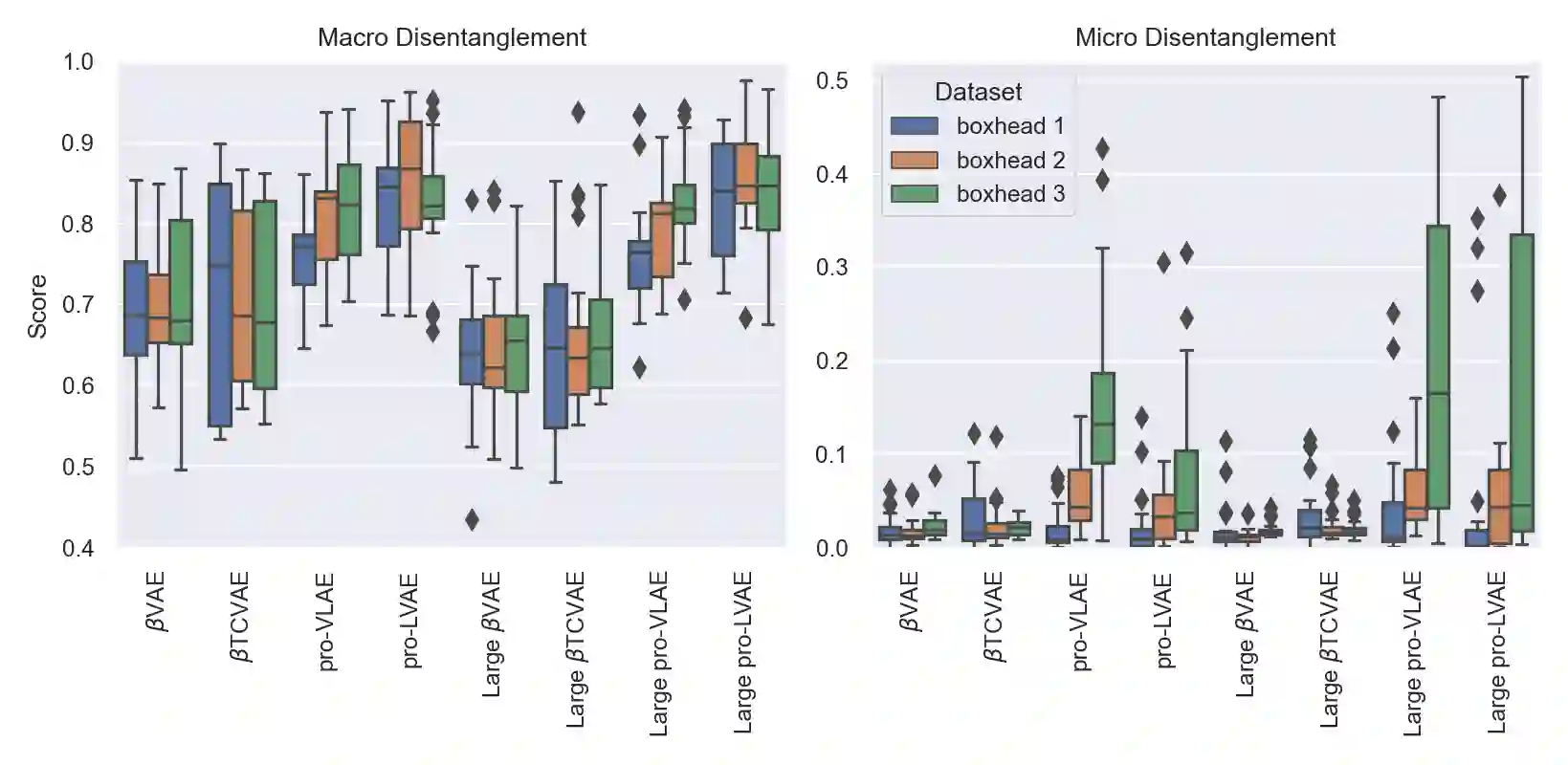
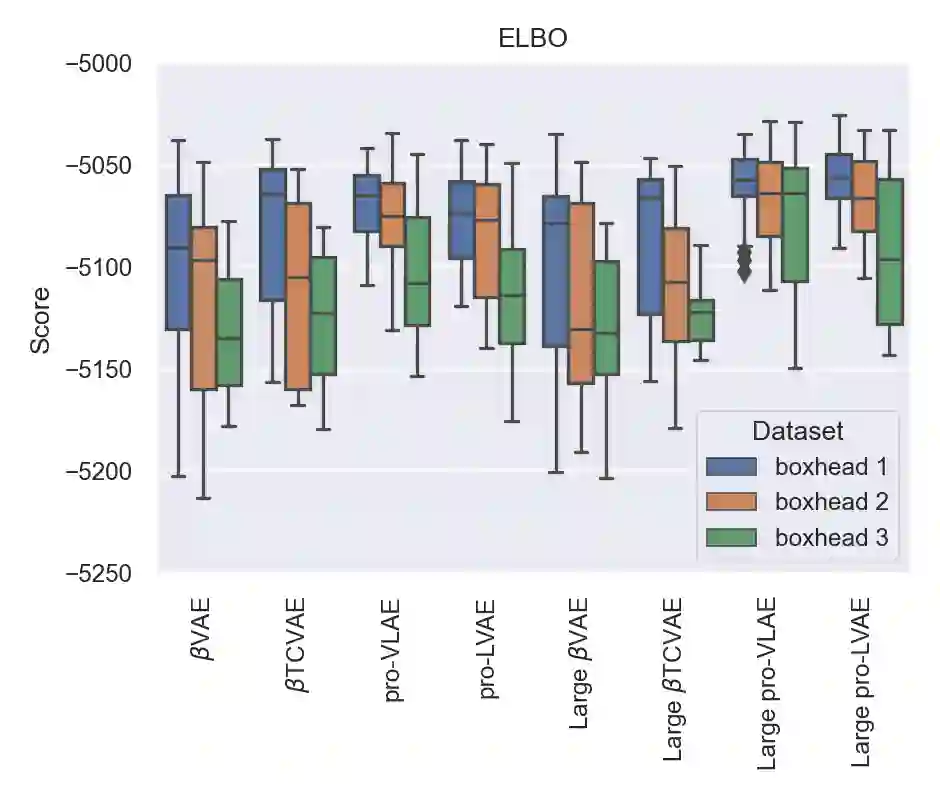
Disentanglement is hypothesized to be beneficial towards a number of downstream tasks. However, a common assumption in learning disentangled representations is that the data generative factors are statistically independent. As current methods are almost solely evaluated on toy datasets where this ideal assumption holds, we investigate their performance in hierarchical settings, a relevant feature of real-world data. In this work, we introduce Boxhead, a dataset with hierarchically structured ground-truth generative factors. We use this novel dataset to evaluate the performance of state-of-the-art autoencoder-based disentanglement models and observe that hierarchical models generally outperform single-layer VAEs in terms of disentanglement of hierarchically arranged factors.
翻译:分解被假定为有利于一些下游任务。然而,在学习分解表征中,一个共同的假设是,数据遗传因素在统计上是独立的。由于目前的方法几乎完全评价于这个理想假设所持有的玩具数据集,因此我们调查它们在等级设置中的性能,这是真实世界数据的一个相关特征。在这项工作中,我们引入了Boxhead,这是一个带有分级结构的地面真真知灼见因素的数据集。我们使用这个新数据集来评价以自动解剖器为基础的最先进的分解模型的性能,并观察到等级模型在分解分级因素方面通常优于单层VAs。