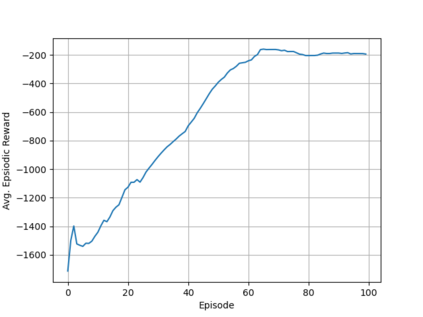
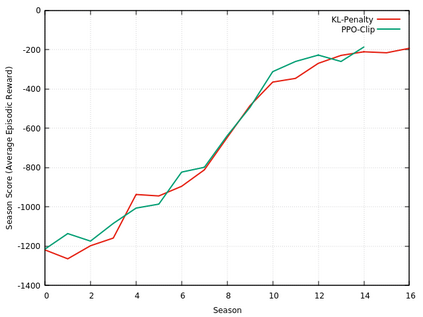
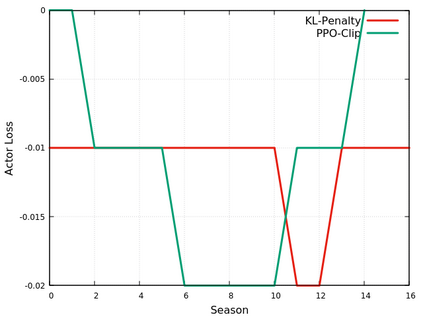
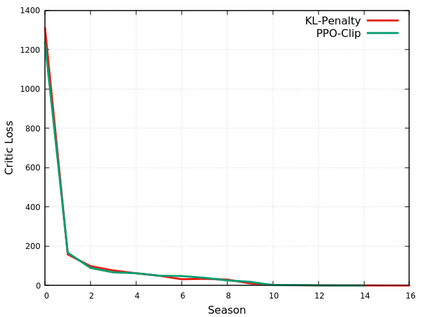
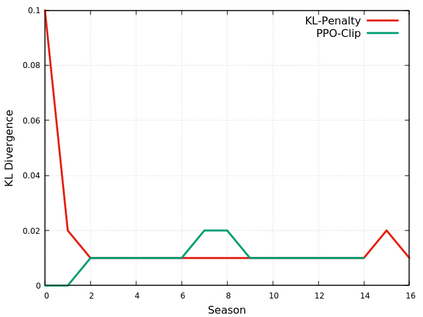
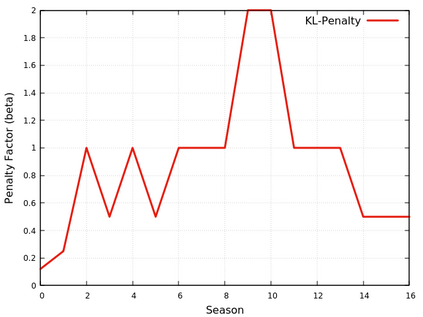
This paper provides the details of implementing two important policy gradient methods to solve the inverted pendulum problem. These are namely the Deep Deterministic Policy Gradient (DDPG) and the Proximal Policy Optimization (PPO) algorithm. The problem is solved by using an actor-critic model where an actor-network is used to learn the policy function and a critic network is to evaluate the actor-network by learning to estimate the Q function. Apart from briefly explaining the mathematics behind these two algorithms, the details of python implementation are provided which helps in demystifying the underlying complexity of the algorithm. In the process, the readers will be introduced to OpenAI/Gym, Tensorflow 2.x and Keras utilities used for implementing the above concepts.
翻译:本文提供了实施两种重要的政策梯度方法解决倒置的钟摆问题的细节。 它们是“ 深确定性政策梯度( DDPG ) ” 和“ 普罗克西马政策优化( PPO ) 算法 ” 。 问题通过使用一个演员- critic 模型来解决, 该模型将使用一个演员- 网络来学习政策功能,而一个评论网络则通过学习来评估演员- 网络来评估 Q 函数。 除了简要解释这两种算法背后的数学外, 还提供 Python 执行的细节, 这有助于解开算法的复杂性。 在此过程中, 读者将被引入 OpenAI/ Gym, Tensorplow 2.x 和 Keras 公用软件, 用于实施上述概念 。