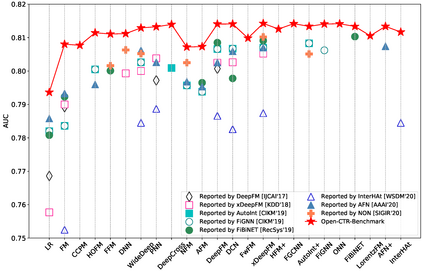
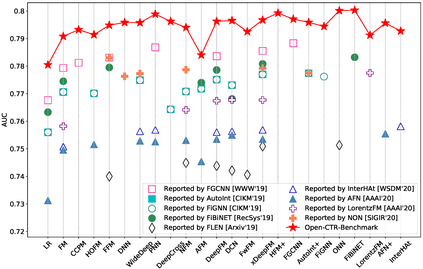
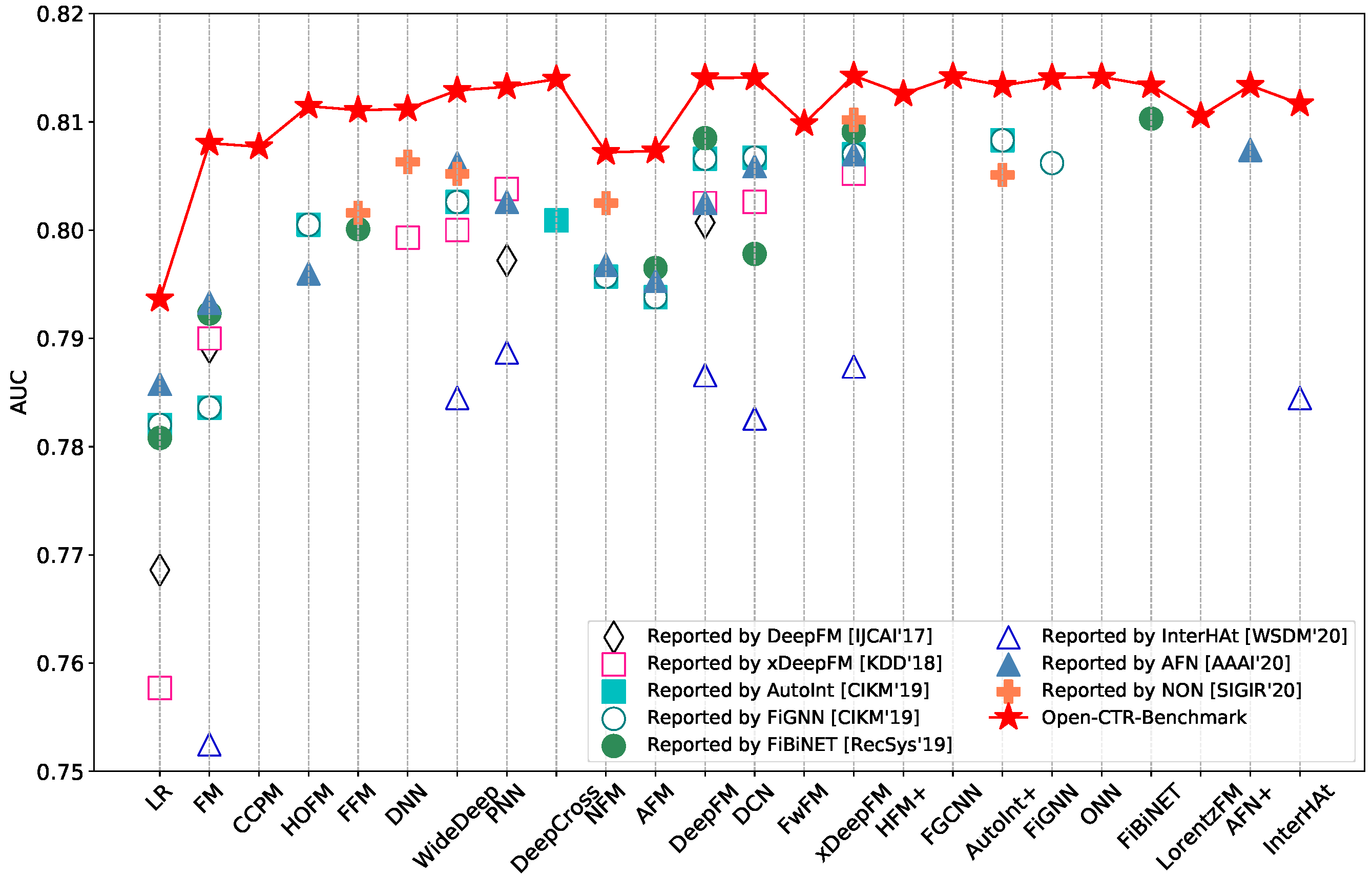
Click-through rate (CTR) prediction is a critical task for many applications, as its accuracy has a direct impact on user experience and platform revenue. In recent years, CTR prediction has been widely studied in both academia and industry, resulting in a wide variety of CTR prediction models. Unfortunately, there is still a lack of standardized benchmarks and uniform evaluation protocols for CTR prediction research. This leads to non-reproducible or even inconsistent experimental results among existing studies, which largely limits the practical value and potential impact of their research. In this work, we aim to perform open benchmarking for CTR prediction and present a rigorous comparison of different models in a reproducible manner. To this end, we ran over 7,000 experiments for more than 12,000 GPU hours in total to re-evaluate 24 existing models on multiple datasets and settings. Surprisingly, our experiments show that with sufficient hyper-parameter search and model tuning, many deep models have smaller differences than expected. The results also reveal that making real progress on the modeling of CTR prediction is indeed a very challenging research task. We believe that our benchmarking work could not only allow researchers to gauge the effectiveness of new models conveniently but also make them fairly compare with the state of the arts. We have publicly released the benchmarking code, evaluation protocols, and experimental settings of our work to promote reproducible research in this field.
翻译:点击率(CTR)预测是许多应用的关键任务,因为其准确性直接影响到用户经验和平台收入。近年来,CTR预测在学术界和工业界都进行了广泛研究,结果产生了各种CTR预测模型。不幸的是,仍然缺乏标准化基准和CTR预测研究的统一评价协议。这导致现有研究之间无法复制甚至不一致的实验结果,这在很大程度上限制了其研究的实际价值和潜在影响。在这项工作中,我们的目标是为CTR预测执行开放的基准,并以可复制的方式对不同的模型进行严格的比较。为此,我们共进行了超过12,000个GPU小时的实验,以重新评价关于多个数据集和设置的24个现有模型。令人惊讶的是,我们的实验表明,如果进行足够的超参数搜索和模型调整,许多深度模型的差别就会小于预期。结果还表明,在CTR预测模型的模型方面取得真正的进展确实是一项非常具有挑战性的研究任务。我们认为,我们的基准工作不仅允许研究人员在12000多个GP小时以上的时间里重新评价关于多个数据集和设置的现有模型的有效性,而且还能够公正地将新的模型的实地进行比较。