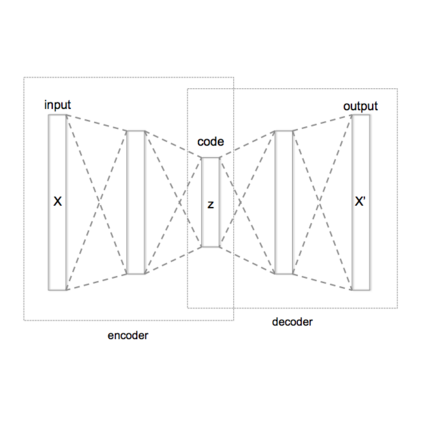
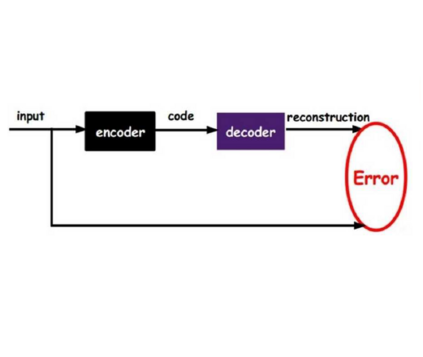
Recently, a generative variational autoencoder (VAE) has been proposed for speech enhancement to model speech statistics. However, this approach only uses clean speech in the training phase, making the estimation particularly sensitive to noise presence, especially in low signal-to-noise ratios (SNRs). To increase the robustness of the VAE, we propose to include noise information in the training phase by using a noise-aware encoder trained on noisy-clean speech pairs. We evaluate our approach on real recordings of different noisy environments and acoustic conditions using two different noise datasets. We show that our proposed noise-aware VAE outperforms the standard VAE in terms of overall distortion without increasing the number of model parameters. At the same time, we demonstrate that our model is capable of generalizing to unseen noise conditions better than a supervised feedforward deep neural network (DNN). Furthermore, we demonstrate the robustness of the model performance to a reduction of the noisy-clean speech training data size.
翻译:最近,有人提议为模拟语音统计而增加一种变异变异自动编码器(VAE),用于增强语言能力,以模拟语音统计。然而,这一方法在培训阶段只使用清洁语言,使估计对噪音的存在特别敏感,特别是在低信号对噪音比率(SNRs)中。为了提高VAE的稳健性,我们提议在培训阶段增加噪音信息,方法是使用在噪音清洁言词配对方面受过训练的防噪音编码器。我们用两个不同的噪音数据集评估我们在不同噪音环境和声音条件下真实录音的方法。我们表明,我们提议的噪音意识VAE在整体扭曲方面超过了标准VAE,而没有增加模型参数的数量。与此同时,我们证明我们的模型能够比有监督的向上深神经网络(DNNN)更好地普及看不见的噪音条件。此外,我们展示了模型性能的强大性能,以降低噪音清洁语言培训数据的规模。