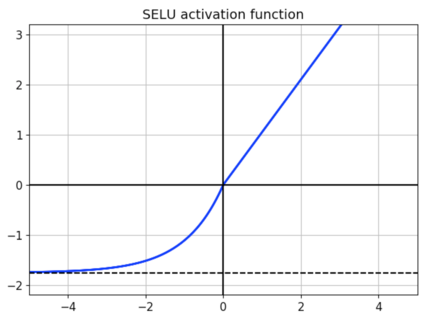
Very deep CNNs achieve state-of-the-art results in both computer vision and speech recognition, but are difficult to train. The most popular way to train very deep CNNs is to use shortcut connections (SC) together with batch normalization (BN). Inspired by Self-Normalizing Neural Networks, we propose the self-normalizing deep CNN (SNDCNN) based acoustic model topology, by removing the SC/BN and replacing the typical RELU activations with scaled exponential linear unit (SELU) in ResNet-50. SELU activations make the network self-normalizing and remove the need for both shortcut connections and batch normalization. Compared to ResNet-50, we can achieve the same or lower word error rate (WER) while at the same time improving both training and inference speed by 60%-80%. We also explore other model inference optimizations to further reduce latency for production use.
翻译:非常深入的有线电视新闻网在计算机视觉和语音识别方面都取得了最先进的成果,但很难培训。最受欢迎的培训非常深入的有线电视网的方法是使用捷径连接(SC)和批量正常化(BN)。在自热神经网络的启发下,我们建议采用基于深度有线电视新闻网(SNDCNNN)的声学模型表,删除SC/BN,用ResNet-50中的缩放指数线单元(SELU)取代典型的RELU激活。 SELU的激活使网络自我正常化,并消除快捷连接和批量正常化的需要。与ResNet-50相比,我们可以达到相同或较低的字误差率(WER),同时将培训和推导速度提高60%-80%。我们还探索其他的推论优化模式,以进一步降低生产使用的拉度。