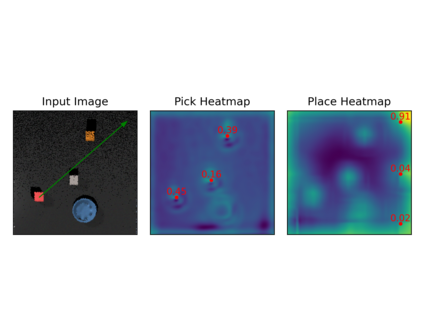
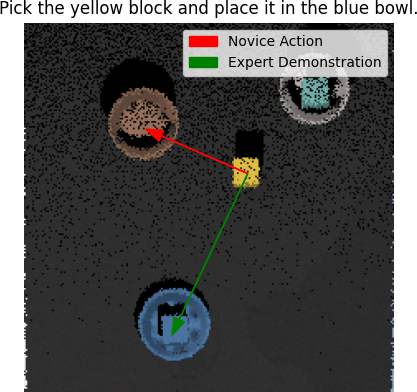
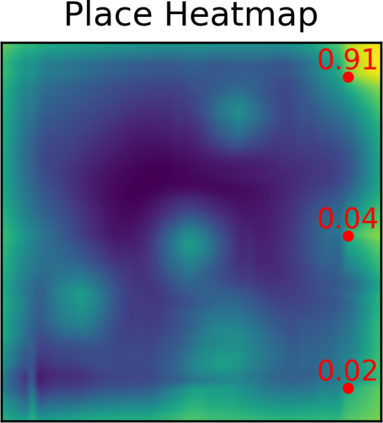
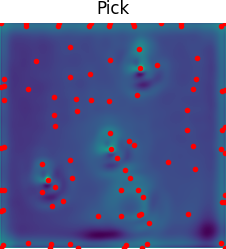
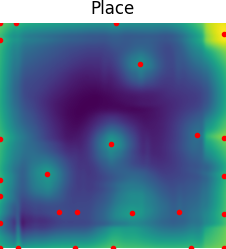
Several recent works show impressive results in mapping language-based human commands and image scene observations to direct robot executable policies (e.g., pick and place poses). However, these approaches do not consider the uncertainty of the trained policy and simply always execute actions suggested by the current policy as the most probable ones. This makes them vulnerable to domain shift and inefficient in the number of required demonstrations. We extend previous works and present the PARTNR algorithm that can detect ambiguities in the trained policy by analyzing multiple modalities in the pick and place poses using topological analysis. PARTNR employs an adaptive, sensitivity-based, gating function that decides if additional user demonstrations are required. User demonstrations are aggregated to the dataset and used for subsequent training. In this way, the policy can adapt promptly to domain shift and it can minimize the number of required demonstrations for a well-trained policy. The adaptive threshold enables to achieve the user-acceptable level of ambiguity to execute the policy autonomously and in turn, increase the trustworthiness of our system. We demonstrate the performance of PARTNR in a table-top pick and place task.
翻译:最近的一些工作显示,在绘制基于语言的人类指令和图像观测以指导机器人可执行的政策(例如,选取和位置构成)方面,取得了令人印象深刻的成果。然而,这些方法并不考虑经过培训的政策的不确定性,而只是总是执行目前政策所建议的最有可能的行动。这使得它们容易发生域变换,所需演示的数量效率低下。我们延长了以前的工作,并提出了 " PartNR算法 ",该算法可以通过分析选取和地点的多种模式来发现经过培训的政策的模糊性。 " PartNR " 使用适应性、敏感性和格子功能,确定是否需要额外的用户演示。用户演示被汇总到数据集中,并用于随后的培训。这样,该政策可以迅速适应到域变换,并最大限度地减少需要经过良好培训的政策的演示数量。适应性阈值能够达到用户接受的模糊性水平,以便自主和反过来执行政策,提高我们系统的信任度。我们用桌面选取和地点任务展示了 " PartNR " 的绩效。