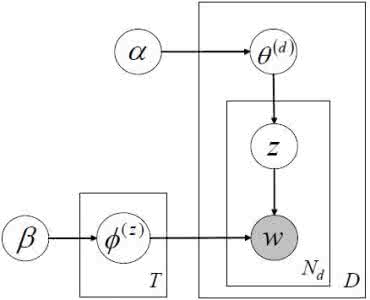
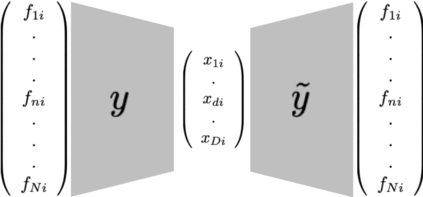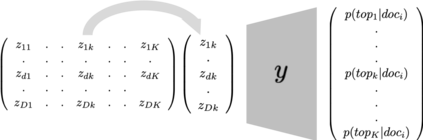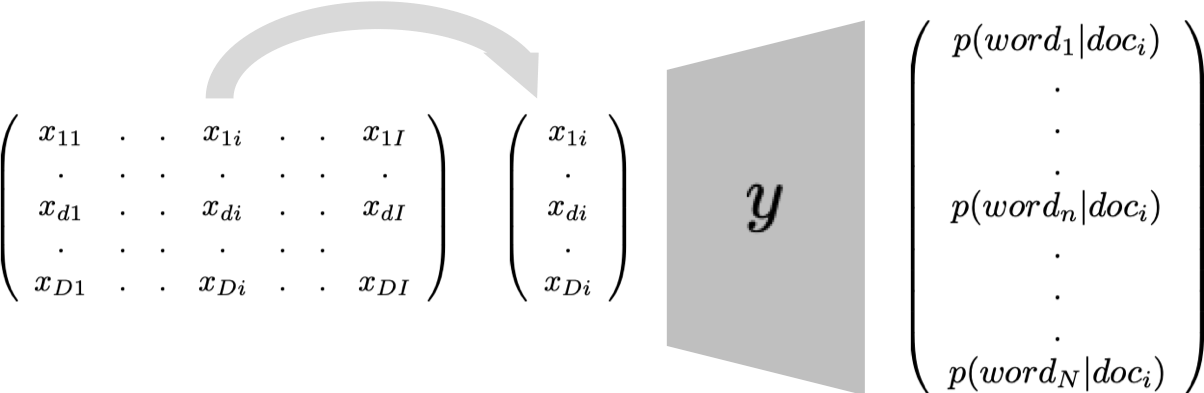In this paper we present a model for unsupervised topic discovery in texts corpora. The proposed model uses documents, words, and topics lookup table embedding as neural network model parameters to build probabilities of words given topics, and probabilities of topics given documents. These probabilities are used to recover by marginalization probabilities of words given documents. For very large corpora where the number of documents can be in the order of billions, using a neural auto-encoder based document embedding is more scalable then using a lookup table embedding as classically done. We thus extended the lookup based document embedding model to continuous auto-encoder based model. Our models are trained using probabilistic latent semantic analysis (PLSA) assumptions. We evaluated our models on six datasets with a rich variety of contents. Conducted experiments demonstrate that the proposed neural topic models are very effective in capturing relevant topics. Furthermore, considering perplexity metric, conducted evaluation benchmarks show that our topic models outperform latent Dirichlet allocation (LDA) model which is classically used to address topic discovery tasks.
翻译:在本文中,我们提出了一个在文本公司中进行不受监督的专题发现模型。 拟议的模型使用文档、 单词和主题查找表作为神经网络模型参数嵌入神经网络参数, 以建立给定主题的单词概率和给定文件的概率。 这些概率用于通过给定文件的单词的边缘化概率来恢复。 对于巨大的公司来说, 其文件数量可以达到数十亿左右, 使用以神经自动编码为基础的文件嵌入, 比较容易缩放, 然后使用古典化的外观表格嵌入。 因此, 我们把基于外观的文件嵌入模型扩大到基于持续自动编码的模型。 我们的模型是使用概率潜在语系分析( PLSA) 假设来培训的。 我们用具有丰富内容的六个数据集来评估我们的模型。 进行实验表明, 拟议的神经专题模型在捕捉相关专题方面非常有效。 此外, 考虑到不易理解性衡量标准, 进行的评估基准显示, 我们的专题模型比潜在dirichlet分配( LDA) 模型(LDA) 典型用于处理专题发现任务。