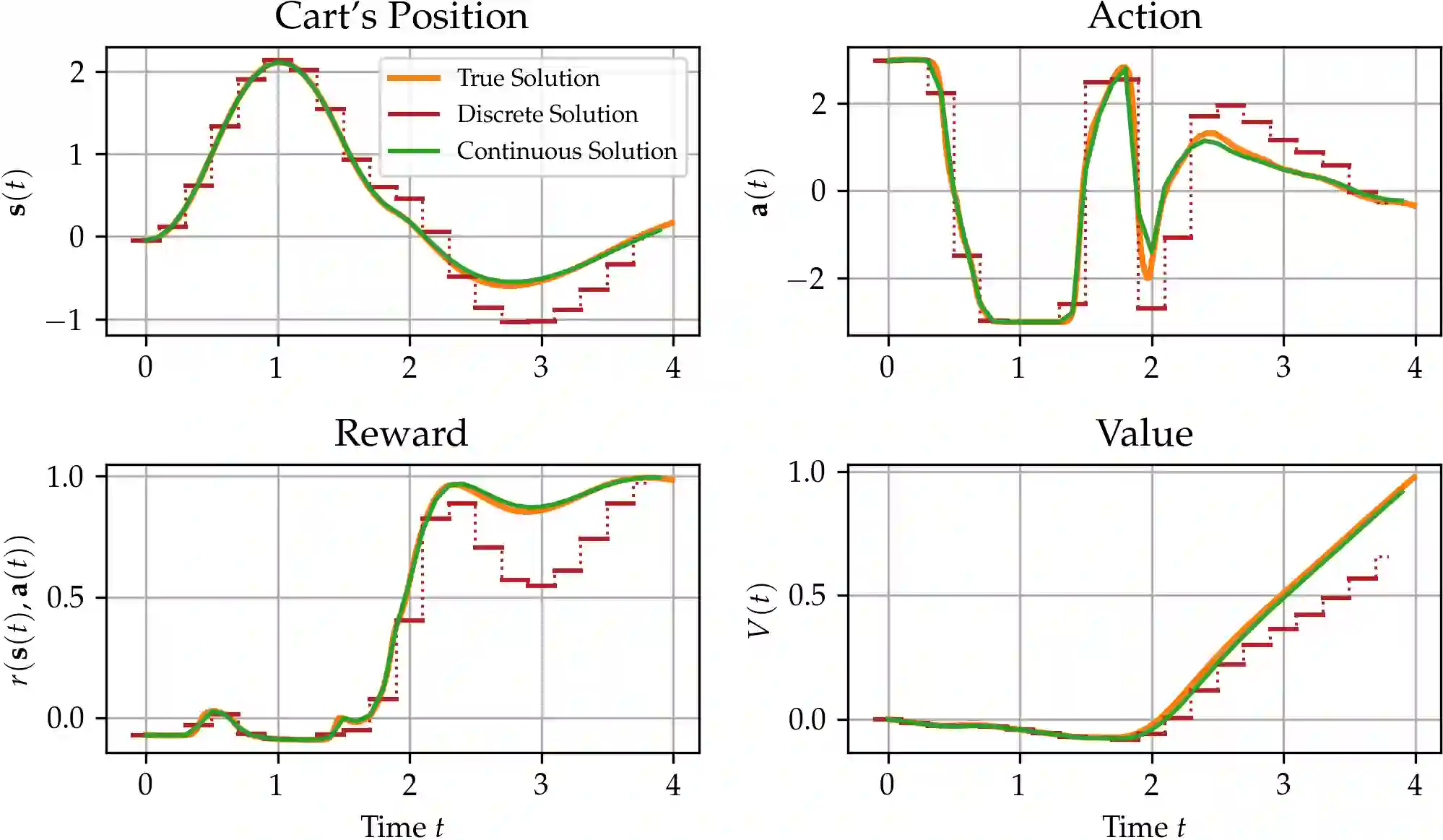
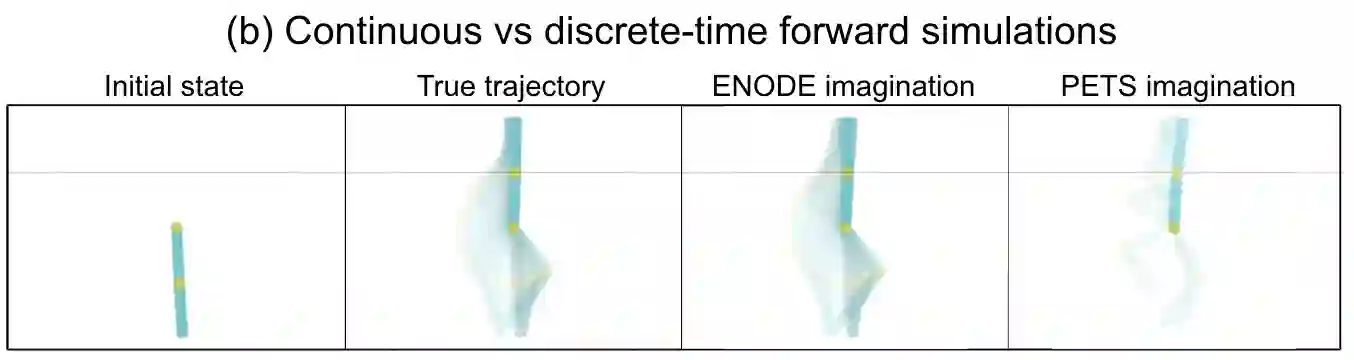
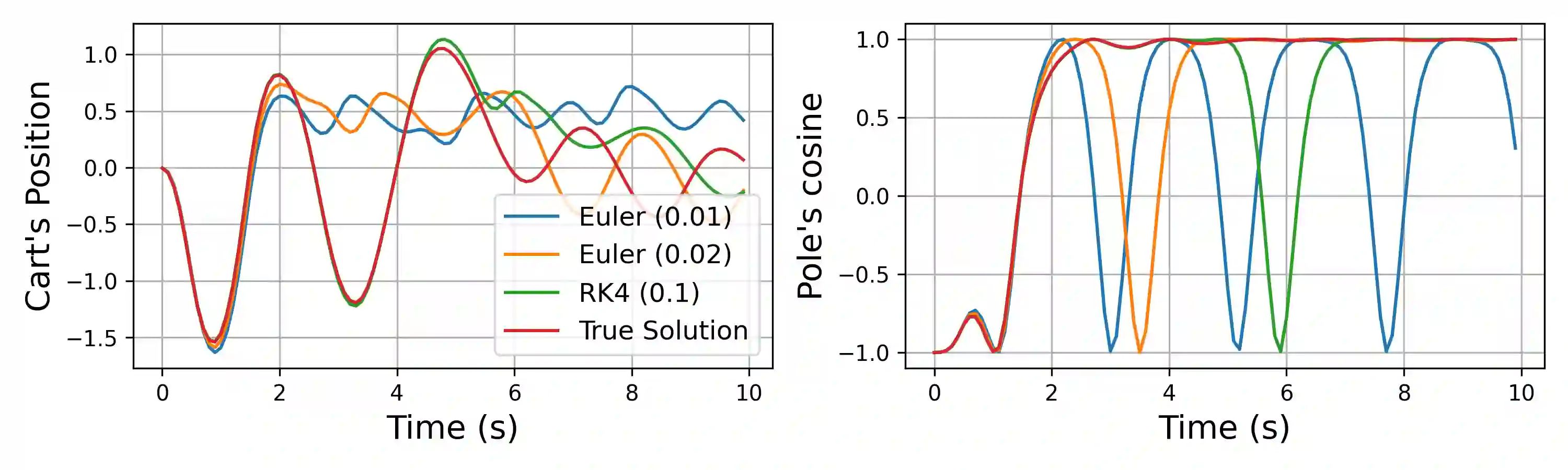
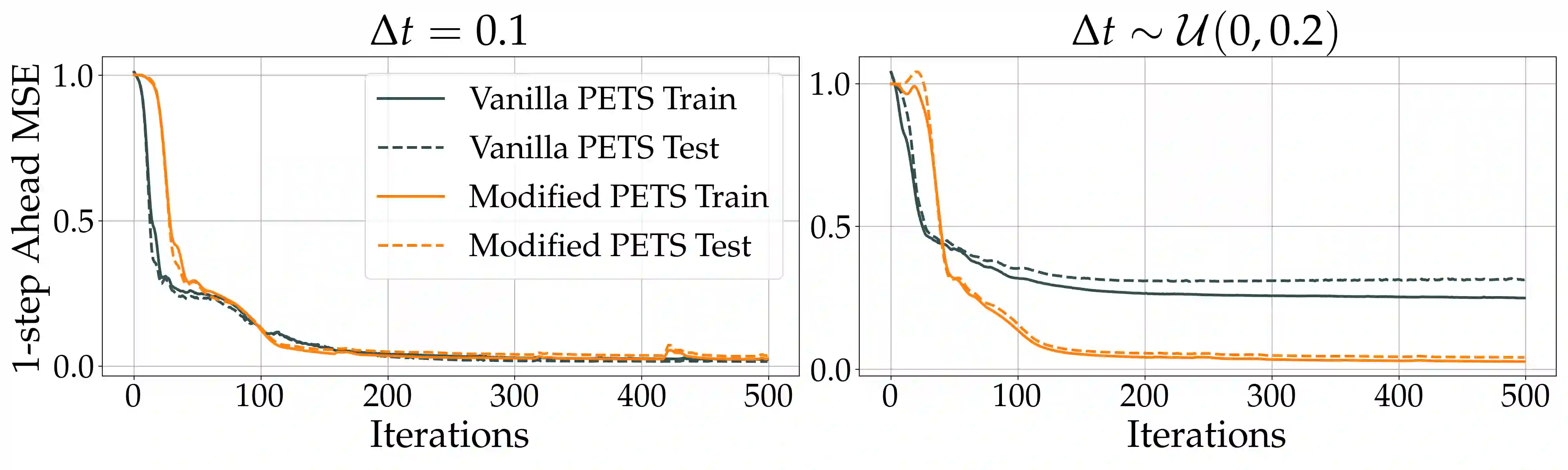
Model-based reinforcement learning (MBRL) approaches rely on discrete-time state transition models whereas physical systems and the vast majority of control tasks operate in continuous-time. To avoid time-discretization approximation of the underlying process, we propose a continuous-time MBRL framework based on a novel actor-critic method. Our approach also infers the unknown state evolution differentials with Bayesian neural ordinary differential equations (ODE) to account for epistemic uncertainty. We implement and test our method on a new ODE-RL suite that explicitly solves continuous-time control systems. Our experiments illustrate that the model is robust against irregular and noisy data, is sample-efficient, and can solve control problems which pose challenges to discrete-time MBRL methods.
翻译:基于模型的强化学习(MBRL)方法依赖离散时间状态过渡模式,而物理系统和绝大多数控制任务则在连续时间运作。为了避免基础过程的时间分解近似,我们提议基于新型的行为者-批评方法的连续时间MBRL框架。我们的方法还推断出与贝叶斯神经普通差异方程式(ODE)存在未知的状态演变差异,以说明认知不确定性。我们实施并测试了我们的方法,在新的ODE-RL套件上明确解决了连续时间控制系统。我们的实验表明,该模式对异常和吵闹的数据是强有力的,具有抽样效率,能够解决对离散时间的MBRL方法构成挑战的控制问题。