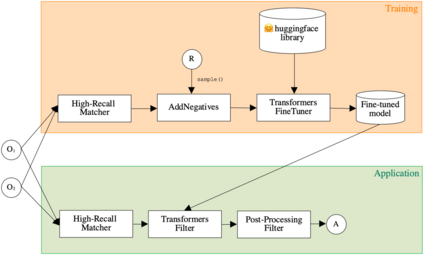
One of the strongest signals for automated matching of ontologies and knowledge graphs are the textual descriptions of the concepts. The methods that are typically applied (such as character- or token-based comparisons) are relatively simple, and therefore do not capture the actual meaning of the texts. With the rise of transformer-based language models, text comparison based on meaning (rather than lexical features) is possible. In this paper, we model the ontology matching task as classification problem and present approaches based on transformer models. We further provide an easy to use implementation in the MELT framework which is suited for ontology and knowledge graph matching. We show that a transformer-based filter helps to choose the correct correspondences given a high-recall alignment and already achieves a good result with simple alignment post-processing methods.
翻译:自动匹配本体和知识图表的最强烈信号之一是对概念的文字描述。通常采用的方法(例如基于字符或象征性的比较)相对简单,因此不反映文本的实际含义。随着基于变压器的语言模型的兴起,基于含义(而不是词汇特征)的文本比较是可能的。在本文中,我们将本体匹配任务作为分类问题进行模型,并采用基于变压器模型的方法。我们进一步提供了在适合用于本体和知识图表匹配的MELT框架中实施的方法的方便。我们表明,基于变压器的过滤器有助于在高调调时选择正确的对应,并且已经以简单的后处理方法取得良好结果。