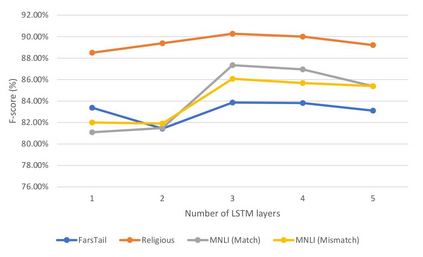
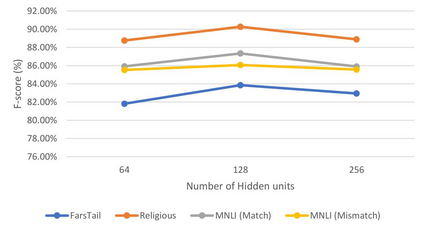
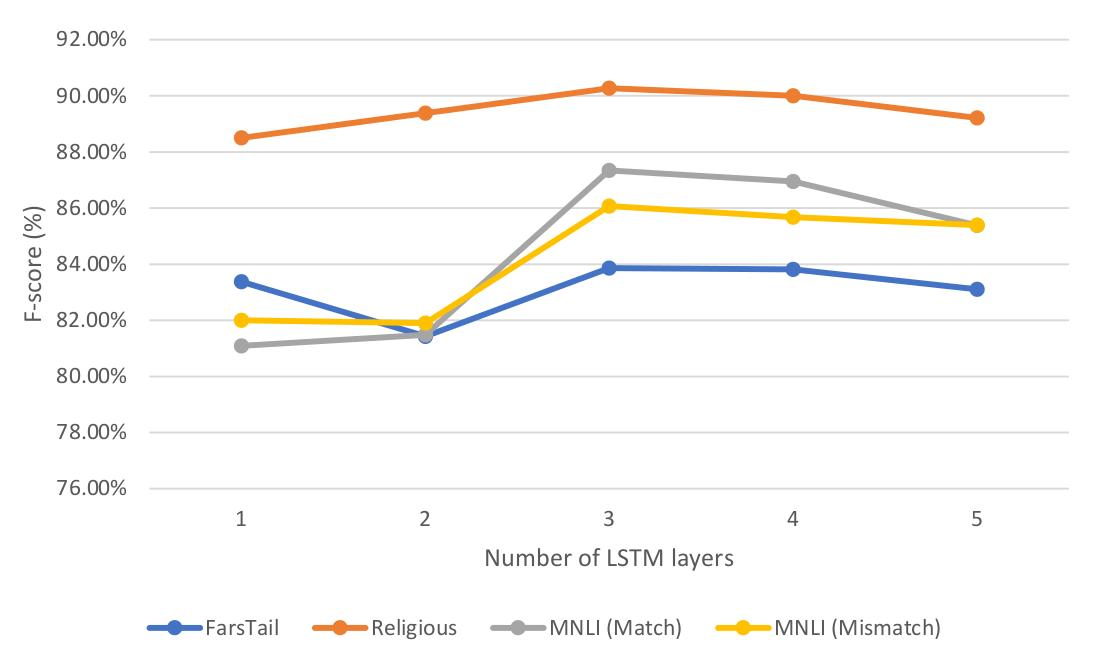
This paper presents a deep neural architecture, for Natural Language Sentence Matching (NLSM) by adding a deep recursive encoder to BERT so called BERT with Deep Recursive Encoder (BERT-DRE). Our analysis of model behavior shows that BERT still does not capture the full complexity of text, so a deep recursive encoder is applied on top of BERT. Three Bi-LSTM layers with residual connection are used to design a recursive encoder and an attention module is used on top of this encoder. To obtain the final vector, a pooling layer consisting of average and maximum pooling is used. We experiment our model on four benchmarks, SNLI, FarsTail, MultiNLI, SciTail, and a novel Persian religious questions dataset. This paper focuses on improving the BERT results in the NLSM task. In this regard, comparisons between BERT-DRE and BERT are conducted, and it is shown that in all cases, BERT-DRE outperforms BERT. The BERT algorithm on the religious dataset achieved an accuracy of 89.70%, and BERT-DRE architectures improved to 90.29% using the same dataset.
翻译:本文展示了一个深心神经结构, 用于自然语言句匹配( NALSM), 其方法是在 BERT 中添加一个叫做 BERT 的深循环编码器。 我们对模型行为的分析表明, BERT 仍然不能完全捕捉文字的复杂内容, 因此在 BERT 上方应用了一个深循环编码器。 3个BI- LSTM 与剩余连接的层用于设计循环编码器, 并且在这个编码器顶部使用一个注意模块。 为了获得最终矢量, 使用了由平均和最大集合组成的集合层。 我们实验了我们的四个基准模型, SNLI、 FarsTail、 MultiNLI、 SciTail 和一个新的波斯宗教问题数据集。 本文侧重于改进 BERT NLSM 任务中的结果。 在这方面, 进行了BERT- DREE 和 BERT 之间的比较, 并且表明, 在所有情况下, BERT- DERD 都超越了BERT 。 在宗教数据设置上, 90- DRA 的算算算方法使用了89- 70 % 和 BERT 。