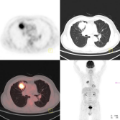
Medical data poses a daunting challenge for AI algorithms: it exists in many different modalities, experiences frequent distribution shifts, and suffers from a scarcity of examples and labels. Recent advances, including transformers and self-supervised learning, promise a more universal approach that can be applied flexibly across these diverse conditions. To measure and drive progress in this direction, we present BenchMD: a benchmark that tests how modality-agnostic methods, including architectures and training techniques (e.g. self-supervised learning, ImageNet pretraining), perform on a diverse array of clinically-relevant medical tasks. BenchMD combines 19 publicly available datasets for 7 medical modalities, including 1D sensor data, 2D images, and 3D volumetric scans. Our benchmark reflects real-world data constraints by evaluating methods across a range of dataset sizes, including challenging few-shot settings that incentivize the use of pretraining. Finally, we evaluate performance on out-of-distribution data collected at different hospitals than the training data, representing naturally-occurring distribution shifts that frequently degrade the performance of medical AI models. Our baseline results demonstrate that no modality-agnostic technique achieves strong performance across all modalities, leaving ample room for improvement on the benchmark. Code is released at https://github.com/rajpurkarlab/BenchMD .
翻译:医疗数据对AI算法提出了极大挑战:存在许多不同的模态、经常发生分布转移和缺乏实例和标签。最近的进展,包括transformers和自监督学习,承诺采用更通用的方法,可在这些不同的条件下灵活应用。为了衡量和推动这种方向的进展,我们提出了BenchMD:一个基准测试,测试模态无关方法(包括体系结构和训练技术(例如自监督学习、ImageNet预训练))在各种临床相关的医学任务中的表现。 BenchMD结合了7种医学模态的19个公共可用数据集,包括1D传感器数据、2D图像和3D容积扫描。我们的基准测试反映了现实世界的数据限制,通过评估各种数据集大小来评估方法,包括具有挑战性的少样本设置,鼓励使用预训练。最后,我们在收集于不同医院的分布数据上评估性能,代表常常降低医疗AI模型性能的自然出现的分布转移。我们的基准结果表明,在所有模态上没有模态无关技术实现了强大的性能,这为基准测试的改进留下了很大的空间。代码在https://github.com/rajpurkarlab/BenchMD释放。