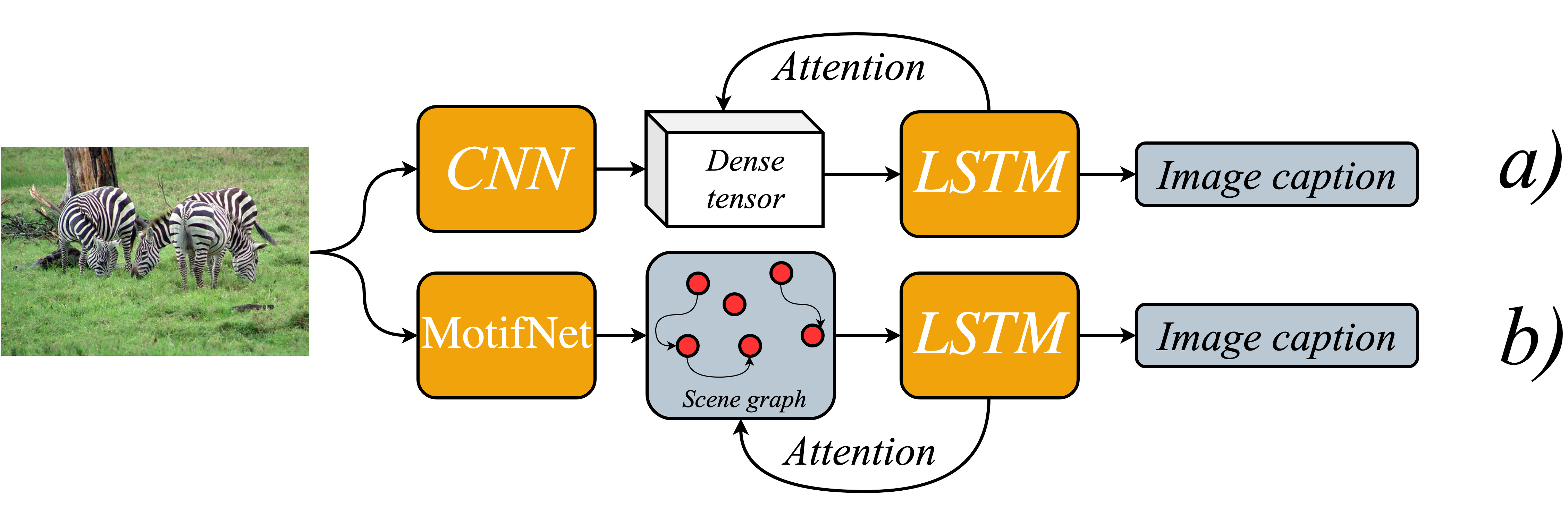
We investigate the incorporation of visual relationships into the task of supervised image caption generation by proposing a model that leverages detected objects and auto-generated visual relationships to describe images in natural language. To do so, we first generate a scene graph from raw image pixels by identifying individual objects and visual relationships between them. This scene graph then serves as input to our graph-to-text model, which generates the final caption. In contrast to previous approaches, our model thus explicitly models the detection of objects and visual relationships in the image. For our experiments we construct a new dataset from the intersection of Visual Genome and MS COCO, consisting of images with both a corresponding gold scene graph and human-authored caption. Our results show that our methods outperform existing state-of-the-art end-to-end models that generate image descriptions directly from raw input pixels when compared in terms of the BLEU and METEOR evaluation metrics.
翻译:我们研究将视觉关系纳入监督图像字幕生成的任务,方法是提出一种模型,利用已检测到的天体和自动生成的视觉关系来用自然语言描述图像。 为此,我们首先通过识别原始图像像素来生成一个场景图, 识别单个天体和它们之间的视觉关系。 这个场景图然后作为图形到文字模型的输入, 生成最终字幕。 与以往的方法不同, 我们的模型因此明确地模拟图像中天体的探测和视觉关系。 对于我们的实验, 我们从视觉基因组和 MS COCO 的交叉点构建了一个新的数据集, 由图像组成, 包括一个相应的金色场景图和人类授权的字幕。 我们的结果显示, 我们的方法超越了现有的最先进的端到端模型, 这些模型直接从原始输入像素中生成图像描述, 用 BLEU 和 METEOR 评估度量来比较 。