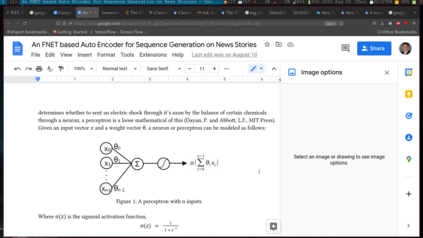
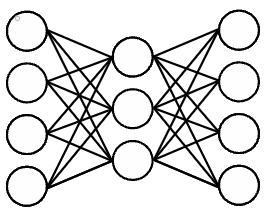
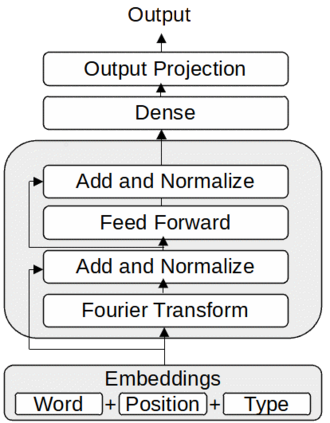
In this paper, we design an auto encoder based off of Google's FNet Architecture in order to generate text from a subset of news stories contained in Google's C4 dataset. We discuss previous attempts and methods to generate text from autoencoders and non LLM Models. FNET poses multiple advantages to BERT based encoders in the realm of efficiency which train 80% faster on GPUs and 70% faster on TPUs. We then compare outputs of how this autencoder perfroms on different epochs. Finally, we analyze what outputs the encoder produces with different seed text.
翻译:在本文中,我们根据谷歌的FNet架构设计了一个自动编码器,以便从谷歌的C4数据集所载的一组新闻报道中生成文本。我们讨论了以前从自动编码器和非LLM模型中生成文本的尝试和方法。FNET给基于BERT的编码器带来了多种好处,在效率方面,它能对GPU进行80%的更快培训,对TPU进行70%的更快培训。然后,我们比较了这个Outenencoder如何从不同角度渗透的输出结果。最后,我们用不同的种子文本分析了编码器产生的结果。