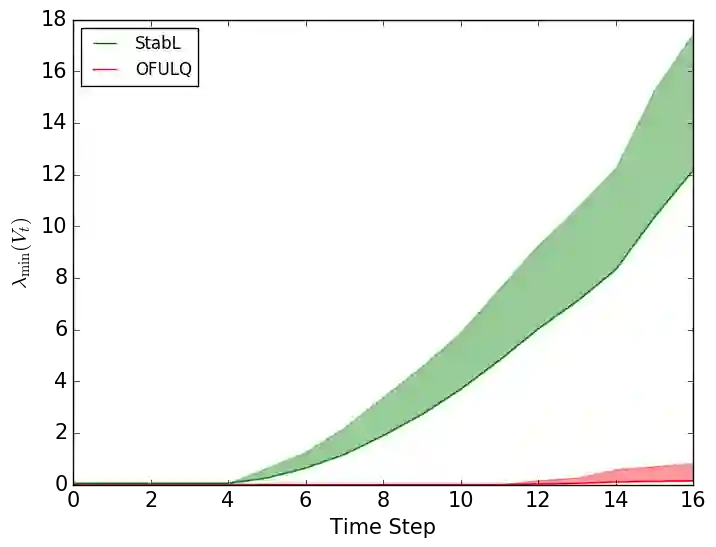
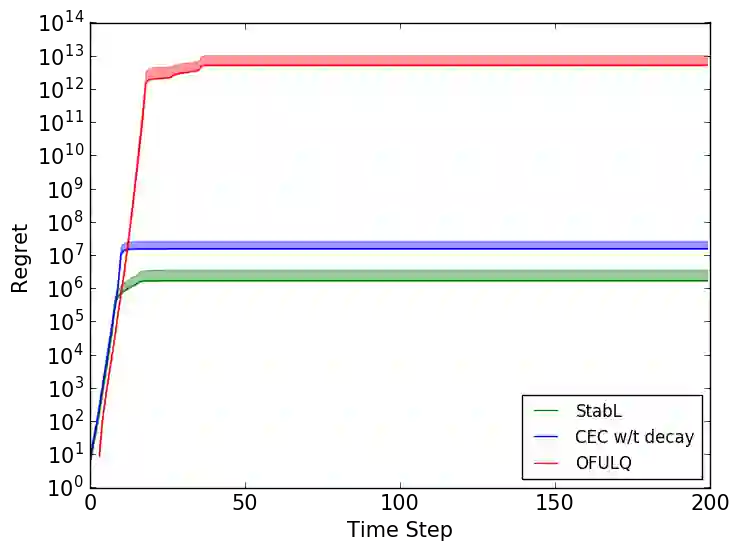
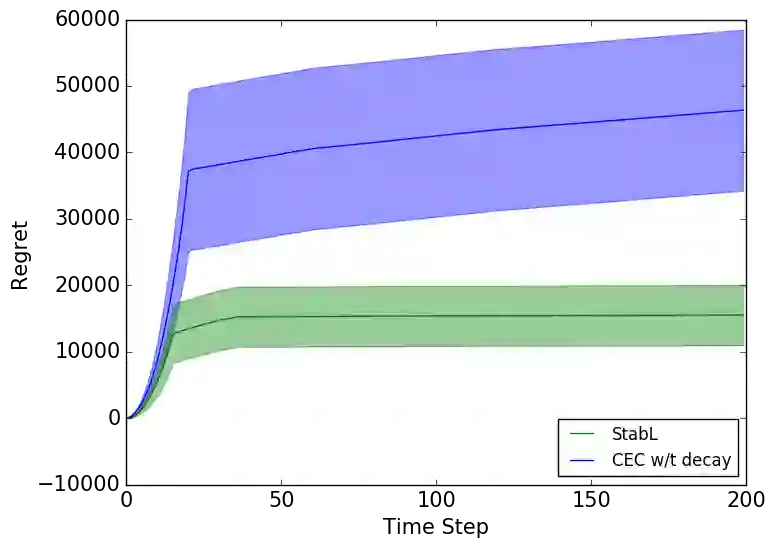
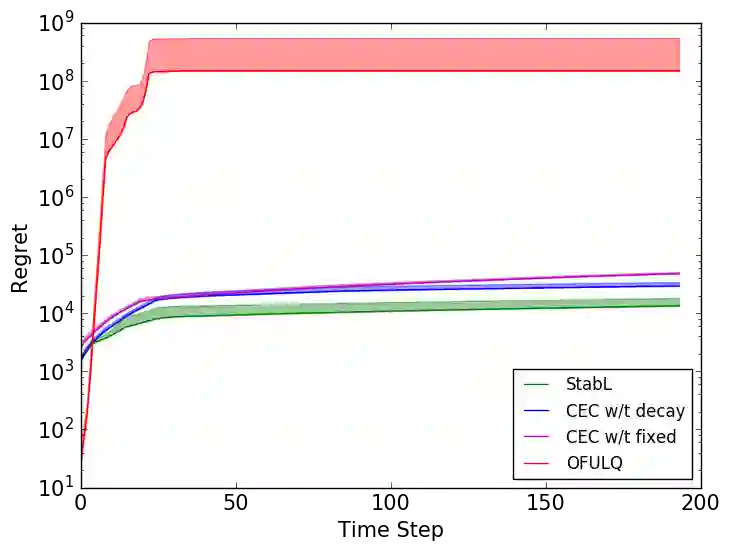
In this work, we study model-based reinforcement learning (RL) in unknown stabilizable linear dynamical systems. When learning a dynamical system, one needs to stabilize the unknown dynamics in order to avoid system blow-ups. We propose an algorithm that certifies fast stabilization of the underlying system by effectively exploring the environment with an improved exploration strategy. We show that the proposed algorithm attains $\tilde{\mathcal{O}}(\sqrt{T})$ regret after $T$ time steps of agent-environment interaction. We also show that the regret of the proposed algorithm has only a polynomial dependence in the problem dimensions, which gives an exponential improvement over the prior methods. Our improved exploration method is simple, yet efficient, and it combines a sophisticated exploration policy in RL with an isotropic exploration strategy to achieve fast stabilization and improved regret. We empirically demonstrate that the proposed algorithm outperforms other popular methods in several adaptive control tasks.
翻译:在这项工作中,我们在未知的可稳定线性动态系统中研究基于模型的强化学习(RL) 。 当学习动态系统时, 需要稳定未知的动态, 以避免系统爆炸。 我们建议一种算法, 通过改进勘探战略, 有效地探索环境, 从而证明基础系统快速稳定。 我们显示, 提议的算法在代理物与环境互动的时间步骤花费T美元后, 取得了$\tilde\mathcal{O ⁇ {( sqrt{T}) 的遗憾。 我们还表明, 提议的算法在问题维度上只有多面依赖性, 使得比先前的方法有指数性改善。 我们改进的勘探方法简单而有效, 并且它把RL的精密勘探政策与异地勘探战略结合起来, 以便快速稳定和改善遗憾。 我们从经验上证明, 提议的算法在几个适应性控制任务中超越了其他受欢迎的方法。