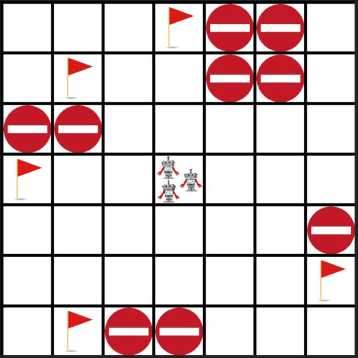
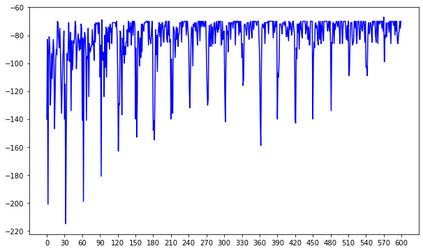
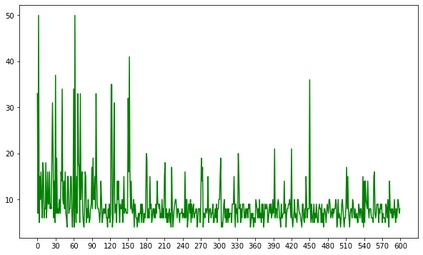
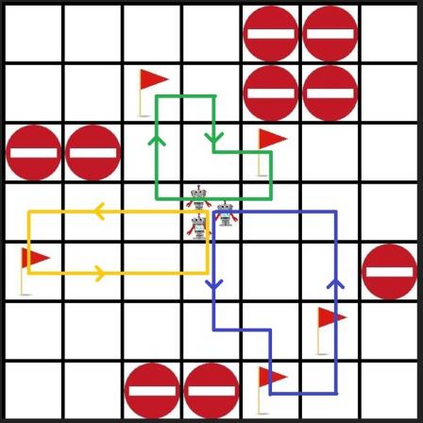
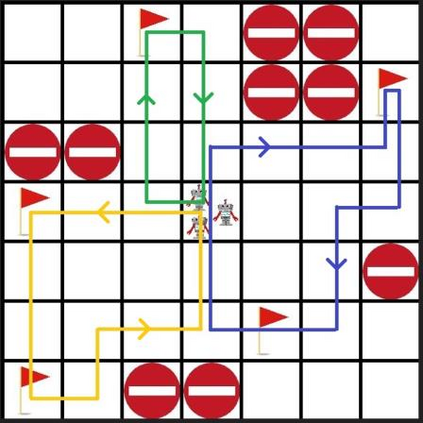
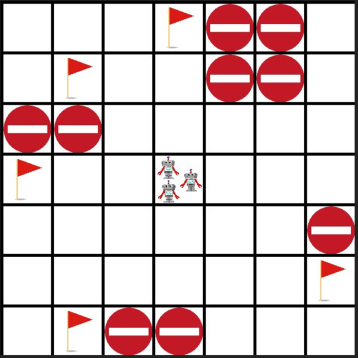
In this paper a deep reinforcement based multi-agent path planning approach is introduced. The experiments are realized in a simulation environment and in this environment different multi-agent path planning problems are produced. The produced problems are actually similar to a vehicle routing problem and they are solved using multi-agent deep reinforcement learning. In the simulation environment, the model is trained on different consecutive problems in this way and, as the time passes, it is observed that the model's performance to solve a problem increases. Always the same simulation environment is used and only the location of target points for the agents to visit is changed. This contributes the model to learn its environment and the right attitude against a problem as the episodes pass. At the end, a model who has already learned a lot to solve a path planning or routing problem in this environment is obtained and this model can already find a nice and instant solution to a given unseen problem even without any training. In routing problems, standard mathematical modeling or heuristics seem to suffer from high computational time to find the solution and it is also difficult and critical to find an instant solution. In this paper a new solution method against these points is proposed and its efficiency is proven experimentally.
翻译:在本文中引入了基于深度强化的多试剂路径规划方法。 实验是在模拟环境中实现的, 在这种环境中产生不同的多试剂路径规划问题。 产生的问题实际上类似于车辆路径问题, 并且通过多试剂深度强化学习加以解决。 在模拟环境中, 模型以这种方式对不同的连续问题进行培训, 并且随着时间的流逝, 观察到模型在解决问题的性能会提高。 总是使用同样的模拟环境, 并且只有代理人访问的目标点的位置才会改变。 这有助于模型学习其环境, 以及当事件过去时对一个问题采取正确的态度。 在本文中, 已经学会了如何解决这一环境中的道路规划或路径问题的模型已经获得了很多经验, 这个模型已经能够找到一个很好和即时的解决方案, 即使没有经过任何培训, 也能够找到一个给人带来的未知的未知问题。 在选择路径的过程中, 标准数学模型或超自然模型似乎会受到高计算时间的困扰, 找到解决方案也是困难和关键的。 在本文中, 一个针对这些点的新方法是实验性的。