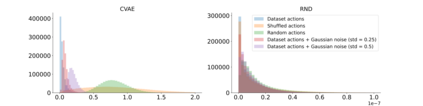
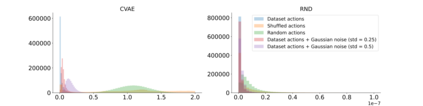
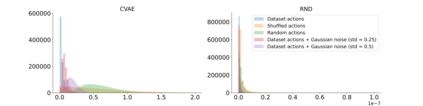
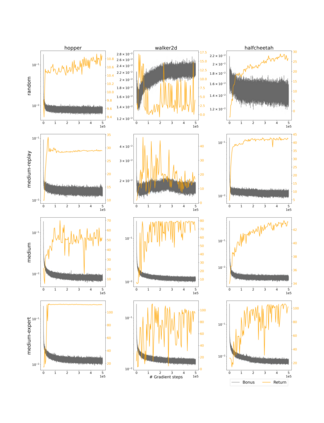
Offline Reinforcement Learning (RL) aims at learning an optimal control from a fixed dataset, without interactions with the system. An agent in this setting should avoid selecting actions whose consequences cannot be predicted from the data. This is the converse of exploration in RL, which favors such actions. We thus take inspiration from the literature on bonus-based exploration to design a new offline RL agent. The core idea is to subtract a prediction-based exploration bonus from the reward, instead of adding it for exploration. This allows the policy to stay close to the support of the dataset. We connect this approach to a more common regularization of the learned policy towards the data. Instantiated with a bonus based on the prediction error of a variational autoencoder, we show that our agent is competitive with the state of the art on a set of continuous control locomotion and manipulation tasks.
翻译:离线强化学习(RL) 旨在从固定的数据集中学习最佳控制,而不必与系统互动。 此设置中的代理机构应当避免选择无法从数据中预测其后果的行动。 这是RL勘探的反面, 有利于此类行动。 因此, 我们从基于奖金的勘探文献中汲取灵感, 设计一个新的离线RL代理。 核心想法是从奖励中减去基于预测的勘探奖金, 而不是添加用于勘探 。 这使得该政策能够接近数据集的支持 。 我们将此方法连接到对数据学习的政策进行更常见的规范化。 基于变换自动编码器预测错误的奖励, 我们显示我们的代理机构在连续控制移动和操作任务上与艺术状态具有竞争力 。