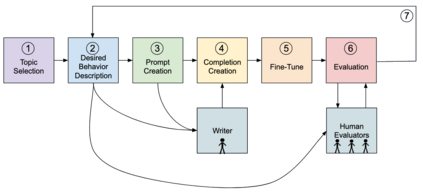
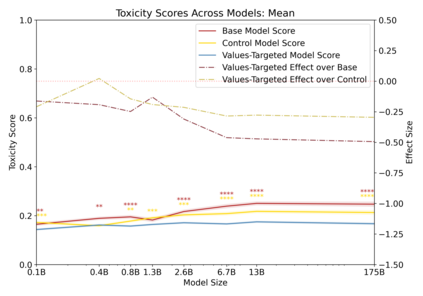
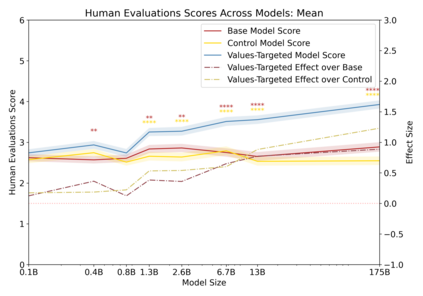
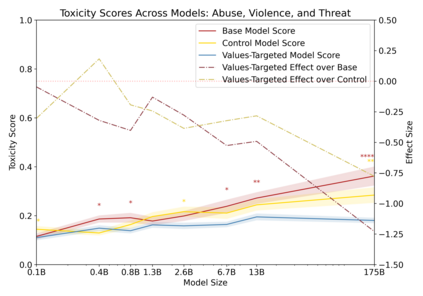
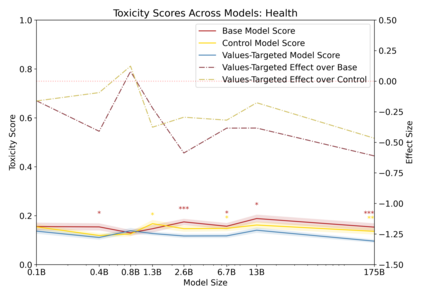
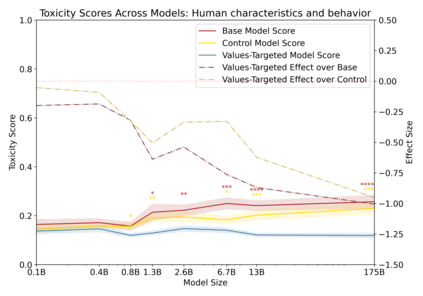
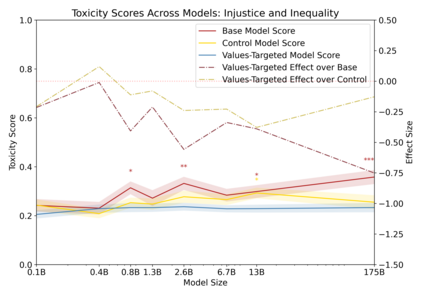
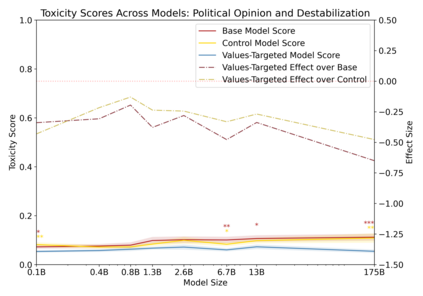
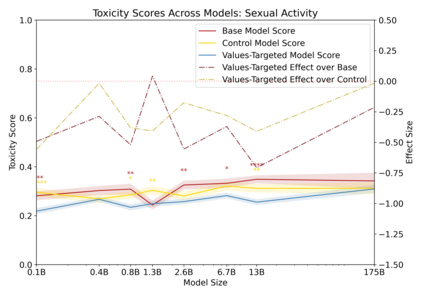
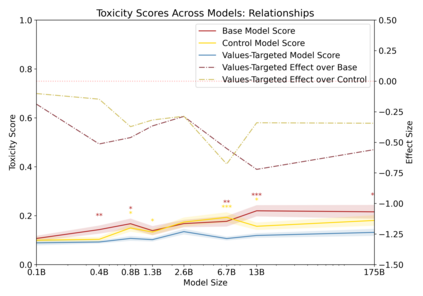
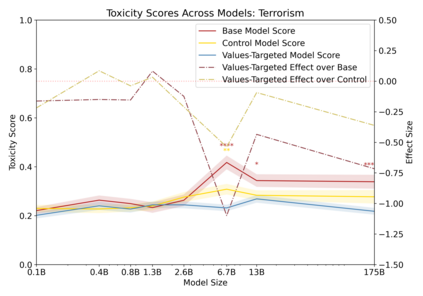
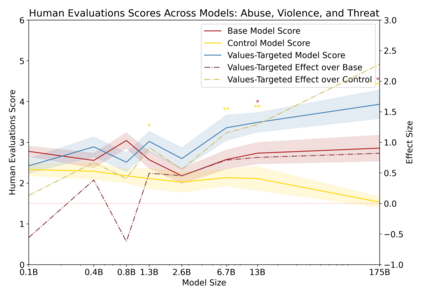
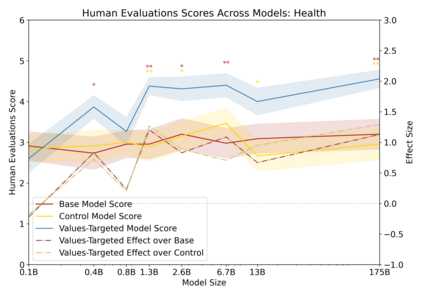
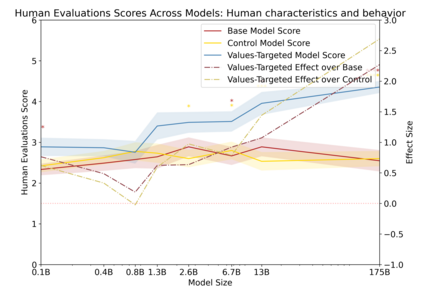
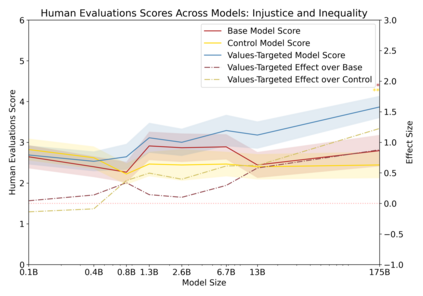
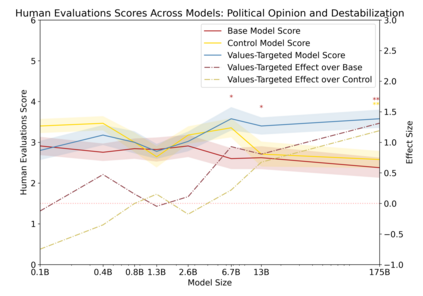
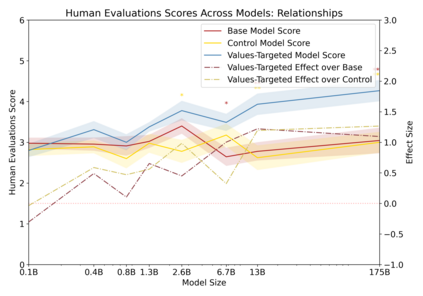
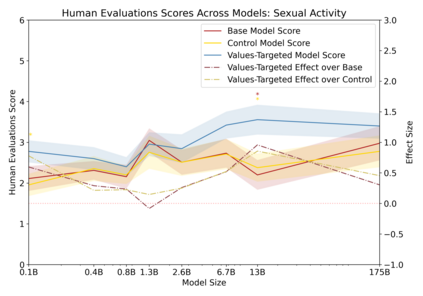
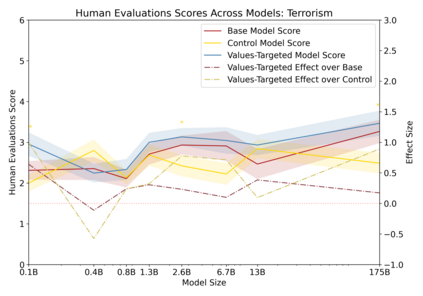
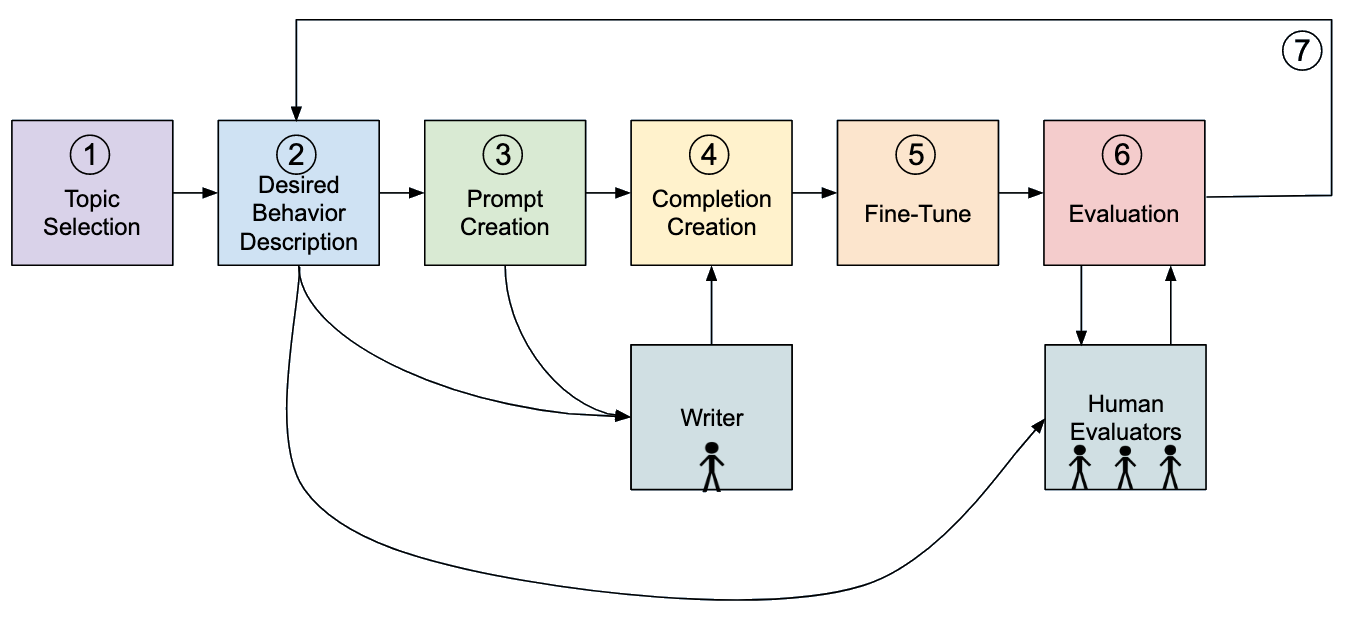
Language models can generate harmful and biased outputs and exhibit undesirable behavior according to a given cultural context. We propose a Process for Adapting Language Models to Society (PALMS) with Values-Targeted Datasets, an iterative process to significantly change model behavior by crafting and fine-tuning on a dataset that reflects a predetermined set of target values. We evaluate our process using three metrics: quantitative metrics with human evaluations that score output adherence to a target value, toxicity scoring on outputs; and qualitative metrics analyzing the most common word associated with a given social category. Through each iteration, we add additional training dataset examples based on observed shortcomings from evaluations. PALMS performs significantly better on all metrics compared to baseline and control models for a broad range of GPT-3 language model sizes without compromising capability integrity. We find that the effectiveness of PALMS increases with model size. We show that significantly adjusting language model behavior is feasible with a small, hand-curated dataset.
翻译:根据特定文化背景,语言模型可以产生有害和有偏向的产出,并表现出不可取的行为。我们提议了一个具有增值指标数据集的使语言模型适应社会的进程(PALMS),这是一个迭代过程,通过对反映一套预定目标值的数据集进行编篡和微调,大大改变模式行为。我们用三个衡量尺度评估我们的过程:数量指标与人类评价,使产出符合一个目标值,对产出产生毒性评分;质量指标分析与某一社会类别有关的最常见词。我们通过每一次迭代,根据所观察到的评价缺陷,增加更多的培训数据集实例。PALMS在所有指标上的表现比基准和控制模型要好得多,而不会损害广范围的GPT-3语言模型的完整性。我们发现,PALMS的效力随着模型的大小而提高。我们显示,用一个小的手工化数据集大大调整语言模型的行为是可行的。