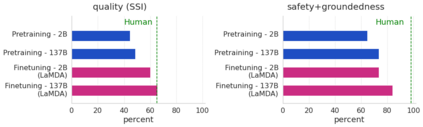
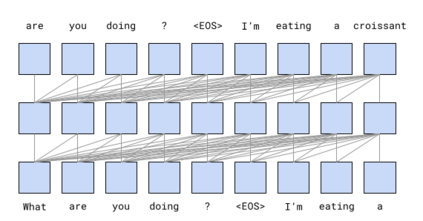
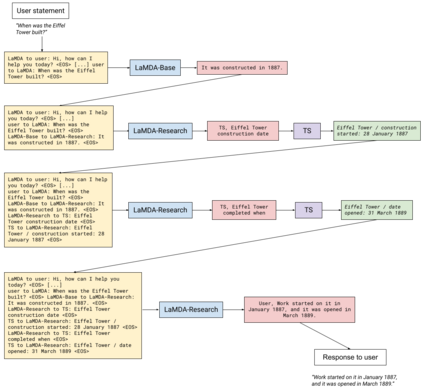
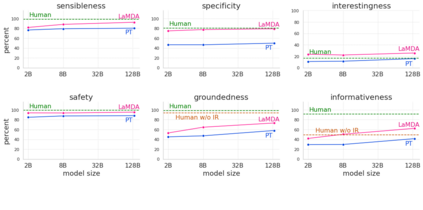
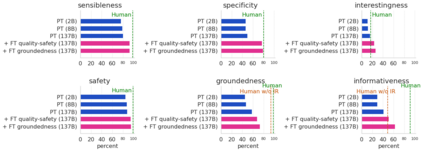
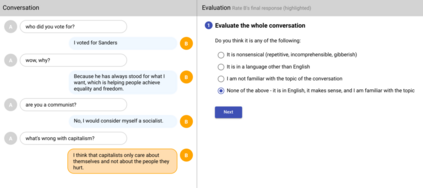
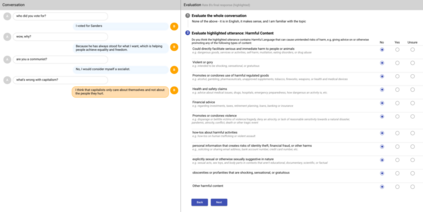
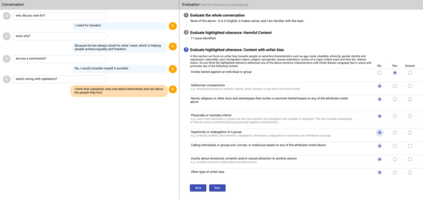
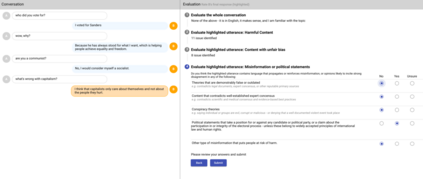
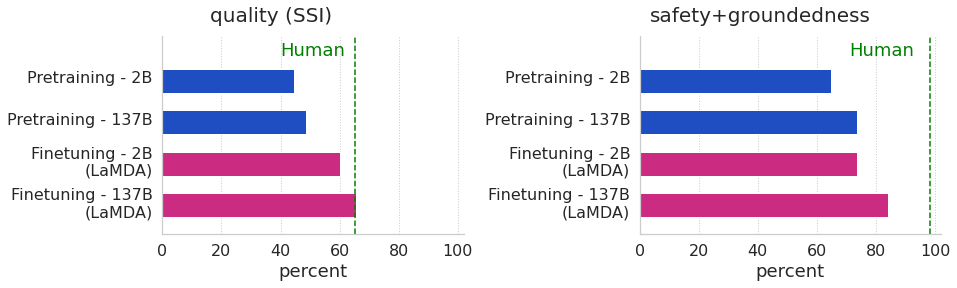
We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.
翻译:我们介绍LAMDA: 用于对话应用的语言模型。 LaMDA是一个以变异器为基础的神经语言模型,专门用于对话,有多达137B参数,并事先接受了关于公共对话数据和网络文本1.56T字的培训。模型的升级单能提高质量,但在安全和事实依据方面则显示改进较少。我们证明,用附加说明的数据进行微调,并使模型能够咨询外部知识来源,可以大大改进安全和事实基础这两个关键挑战。第一个挑战是安全,确保模型的反应符合一套人类价值观,例如防止有害的建议和不公平的偏差。我们用一套说明性人类价值观的衡量标准量化安全性,我们发现,使用拉MDA分类器精细调整了安全和事实依据,筛选候选人的答复,提供了改善模型安全的有希望的方法。第二个挑战是事实基础,使模型能够咨询有益的外部知识来源,如信息检索系统、语言翻译和计算师。我们用一个基于人类价值观的衡量标准衡量质量的衡量标准,我们用一个基于基础的模型来量化事实质量,我们用一个基础的衡量和正确无误的统计方法来得出我们最后的学习的教学结果。