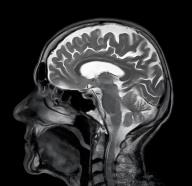
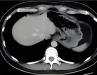
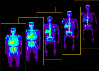
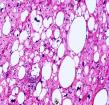
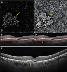
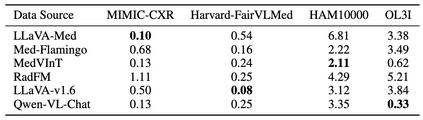
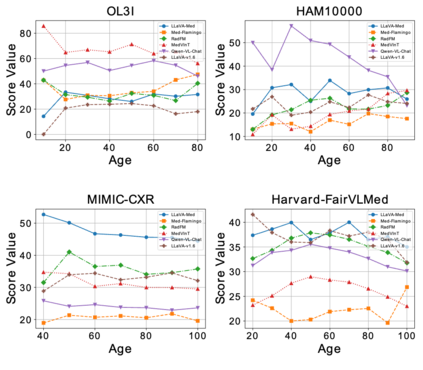
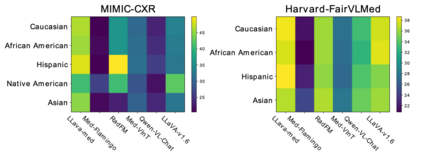
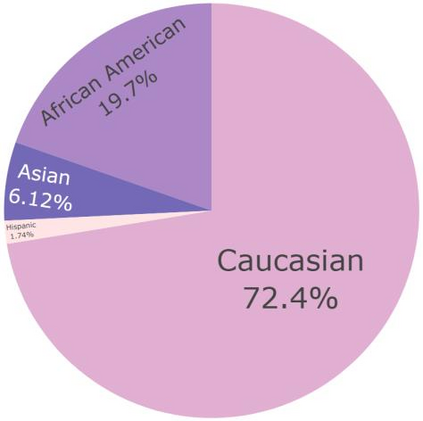
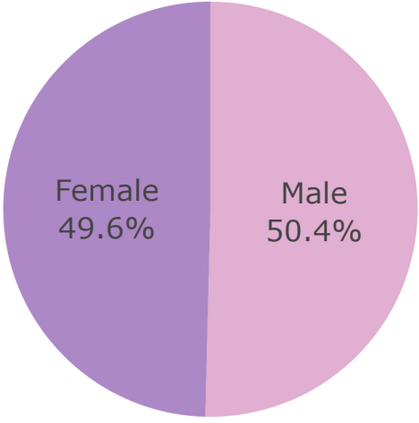
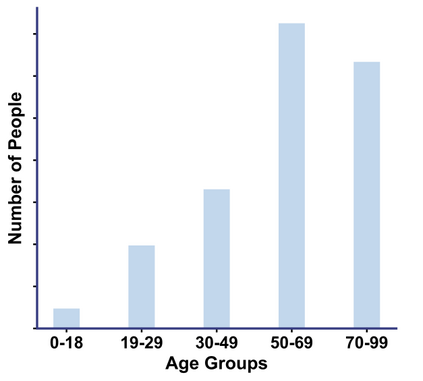
Artificial intelligence has significantly impacted medical applications, particularly with the advent of Medical Large Vision Language Models (Med-LVLMs), sparking optimism for the future of automated and personalized healthcare. However, the trustworthiness of Med-LVLMs remains unverified, posing significant risks for future model deployment. In this paper, we introduce CARES and aim to comprehensively evaluate the Trustworthiness of Med-LVLMs across the medical domain. We assess the trustworthiness of Med-LVLMs across five dimensions, including trustfulness, fairness, safety, privacy, and robustness. CARES comprises about 41K question-answer pairs in both closed and open-ended formats, covering 16 medical image modalities and 27 anatomical regions. Our analysis reveals that the models consistently exhibit concerns regarding trustworthiness, often displaying factual inaccuracies and failing to maintain fairness across different demographic groups. Furthermore, they are vulnerable to attacks and demonstrate a lack of privacy awareness. We publicly release our benchmark and code in https://cares-ai.github.io/.
翻译:暂无翻译