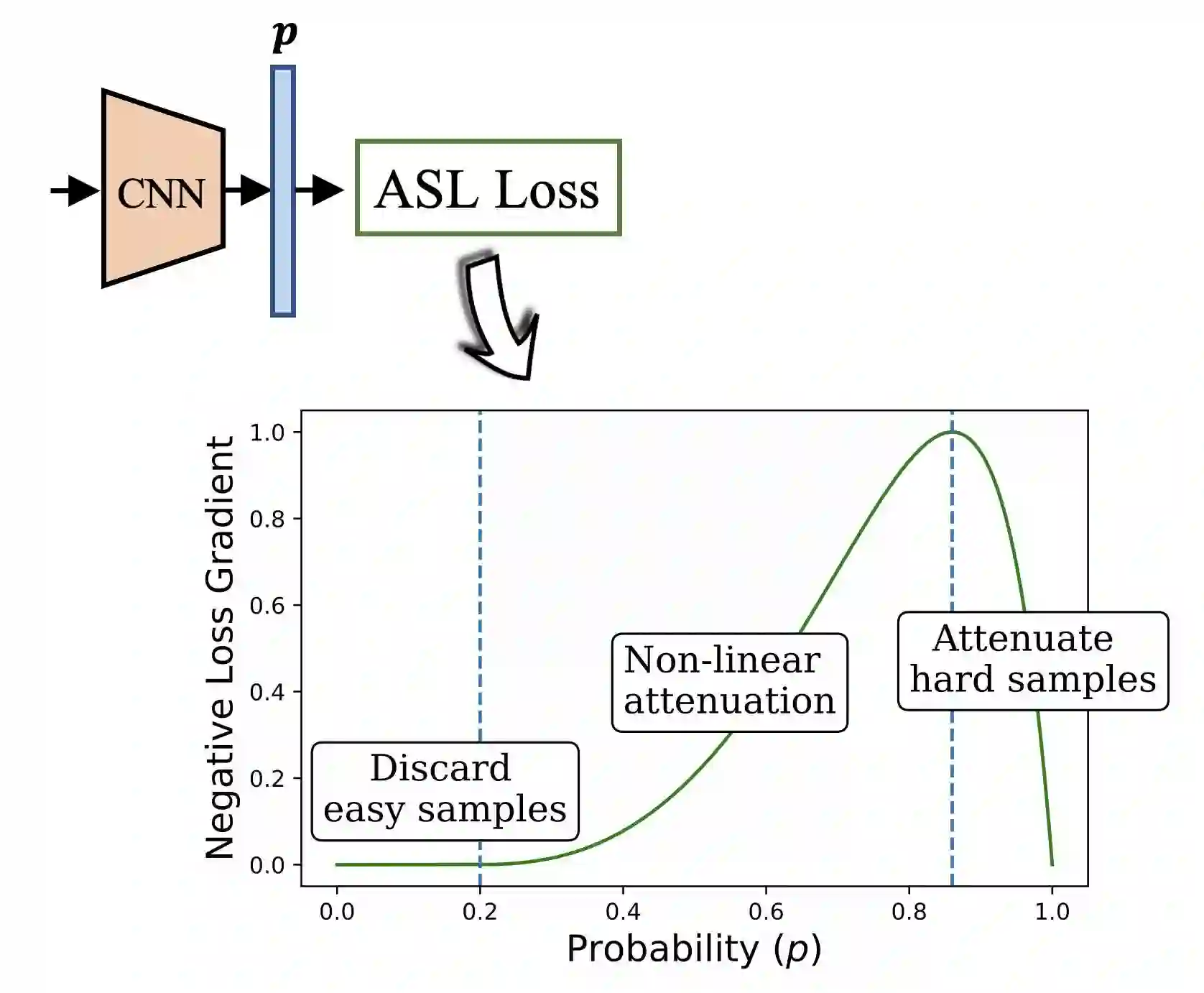
In a typical multi-label setting, a picture contains on average few positive labels, and many negative ones. This positive-negative imbalance dominates the optimization process, and can lead to under-emphasizing gradients from positive labels during training, resulting in poor accuracy. In this paper, we introduce a novel asymmetric loss ("ASL"), which operates differently on positive and negative samples. The loss enables to dynamically down-weights and hard-thresholds easy negative samples, while also discarding possibly mislabeled samples. We demonstrate how ASL can balance the probabilities of different samples, and how this balancing is translated to better mAP scores. With ASL, we reach state-of-the-art results on multiple popular multi-label datasets: MS-COCO, Pascal-VOC, NUS-WIDE and Open Images. We also demonstrate ASL applicability for other tasks, such as single-label classification and object detection. ASL is effective, easy to implement, and does not increase the training time or complexity. Implementation is available at: https://github.com/Alibaba-MIIL/ASL.
翻译:在典型的多标签环境中,图片中平均包含少量正面标签和许多负面标签。这种正反偏向性不平衡主导着优化过程,并可能导致培训期间正面标签的梯度偏小,导致准确性差。在本文中,我们引入了一种新的不对称损失(“ASL ” ),在正反抽样上运行方式不同。这种损失能够动态地降低重量和硬阈值,容易不良的样本,同时丢弃可能贴错标签的样本。我们展示了ASL如何平衡不同样品的概率,以及这种平衡如何转化为更好的 mAP分数。随着ASL,我们在多个流行的多标签数据集(MS-CO、Pascal-VOC、NUS-WIDE和开放图像)上达到了最先进的结果。我们还展示了ASL适用于单标签分类和对象检测等其他任务。ASL是有效的,易于执行,而且不会增加培训时间或复杂性。我们可以看到: https://githhub.com/Alib-MIL。