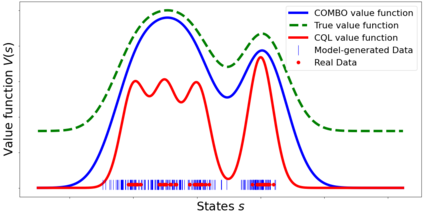
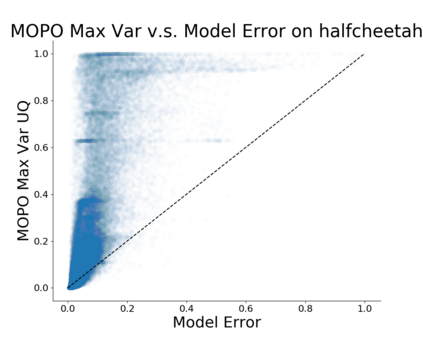
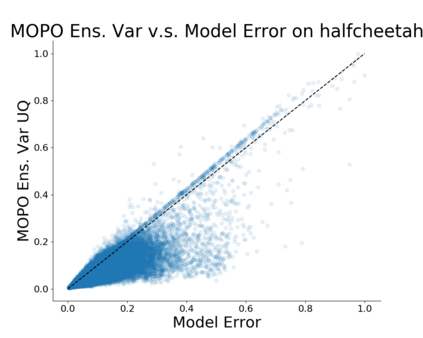
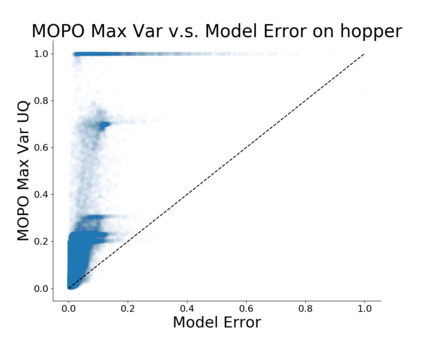
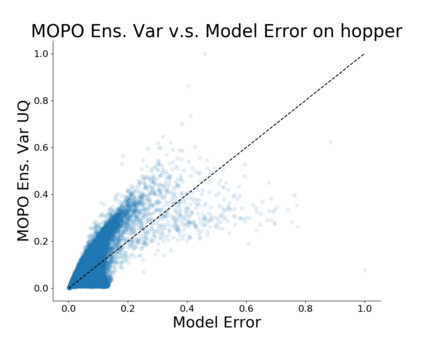
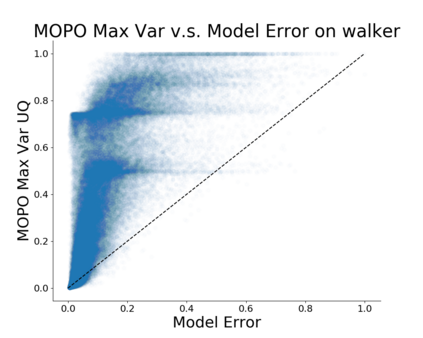
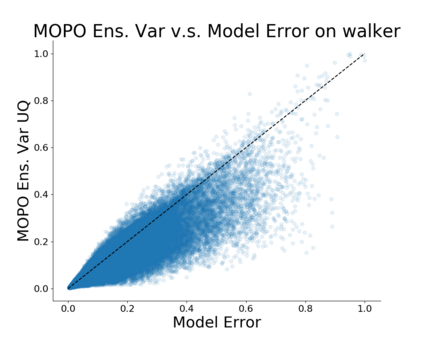
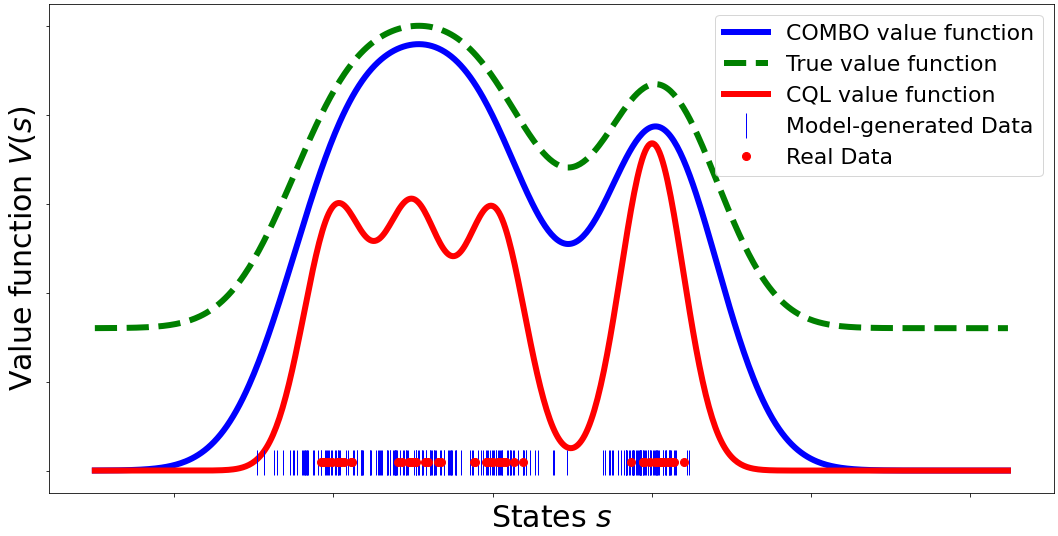
Model-based algorithms, which learn a dynamics model from logged experience and perform some sort of pessimistic planning under the learned model, have emerged as a promising paradigm for offline reinforcement learning (offline RL). However, practical variants of such model-based algorithms rely on explicit uncertainty quantification for incorporating pessimism. Uncertainty estimation with complex models, such as deep neural networks, can be difficult and unreliable. We overcome this limitation by developing a new model-based offline RL algorithm, COMBO, that regularizes the value function on out-of-support state-action tuples generated via rollouts under the learned model. This results in a conservative estimate of the value function for out-of-support state-action tuples, without requiring explicit uncertainty estimation. We theoretically show that our method optimizes a lower bound on the true policy value, that this bound is tighter than that of prior methods, and our approach satisfies a policy improvement guarantee in the offline setting. Through experiments, we find that COMBO consistently performs as well or better as compared to prior offline model-free and model-based methods on widely studied offline RL benchmarks, including image-based tasks.
翻译:以模型为基础的算法,从记录的经验中学习动态模型,并在所学模型下进行某种悲观规划,这些算法已经成为一种很有希望的离线强化学习模式(脱线RL)。然而,这种基于模型的算法的实用变方在纳入悲观主义时依赖于明确的不确定性量化。对复杂的模型,例如深神经网络的不确定性估计可能很困难和不可靠。我们通过开发一个新的基于模型的离线RL算法(COMBO)克服了这一限制,该算法规范了通过在所学模型下推出的离线状态行动图案所产生的支持性支持性国家行动图案的价值功能。这导致对基于支持性国家行动图案的价值功能进行保守的估计,而不需要明确的不确定性估计。我们理论上表明,我们的方法优化了对真实政策价值的较低约束,这种约束比先前方法更为严格,我们的方法在离线环境中满足了政策改进的保证。我们通过实验发现COMBO在广泛研究的离线上基于离线的模型和基于模型的方法,包括基于远线图像基准,始终表现良好或更好。