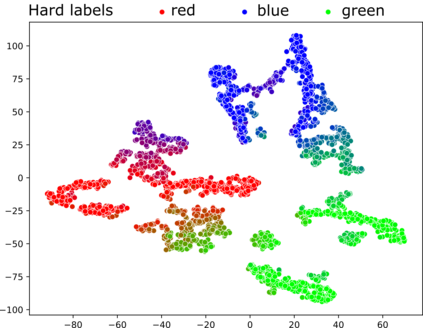
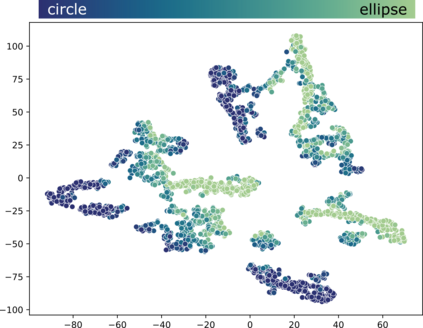
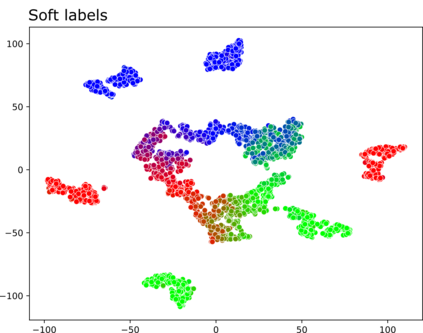
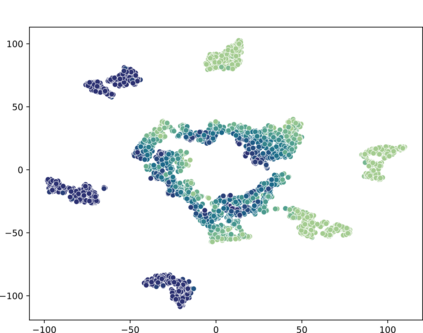
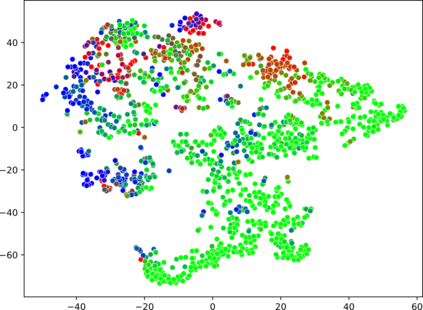
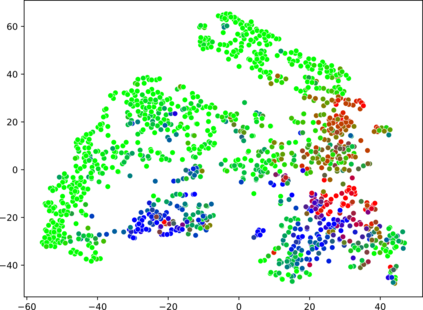
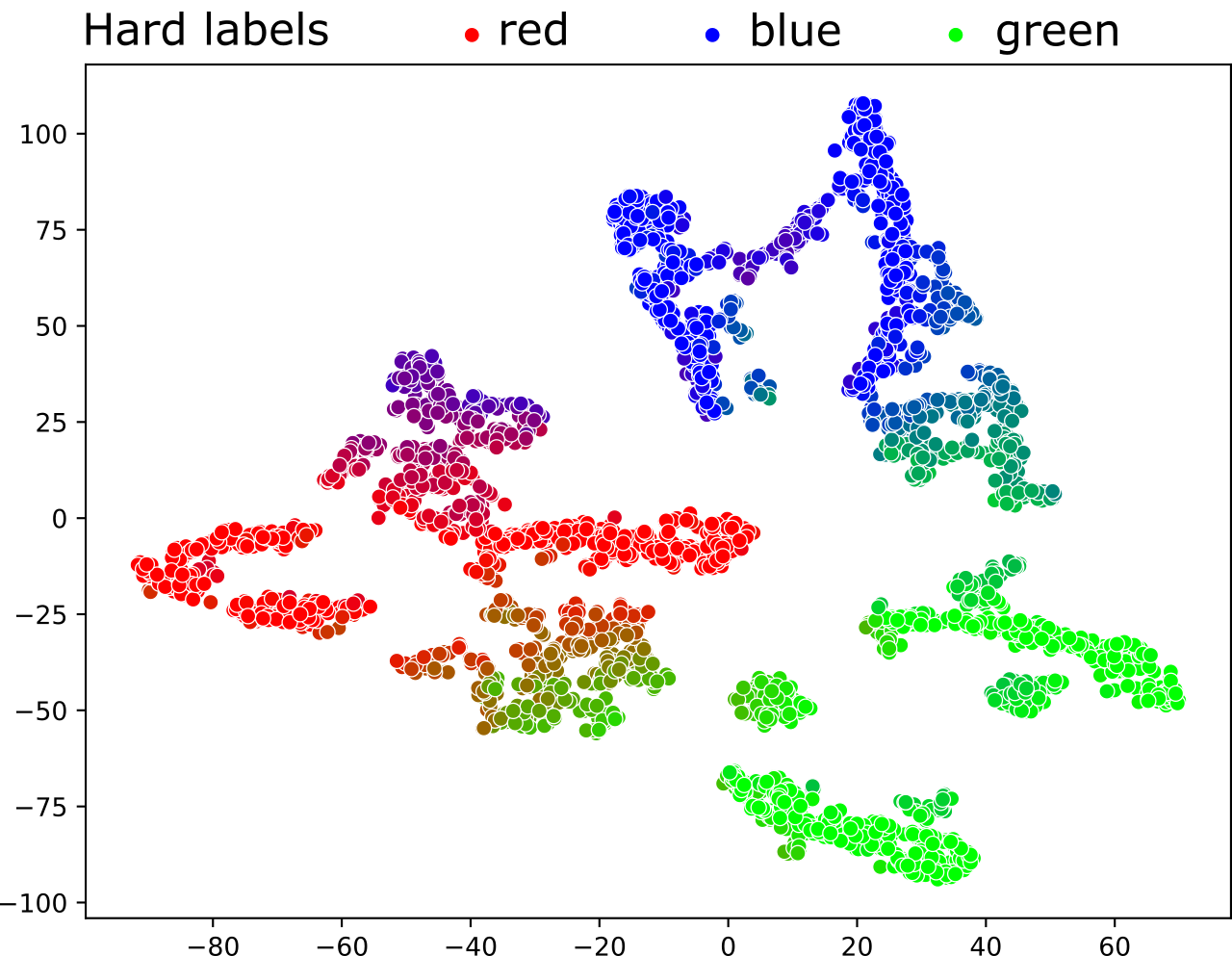
High-quality data is a key aspect of modern machine learning. However, labels generated by humans suffer from issues like label noise and class ambiguities. We raise the question of whether hard labels are sufficient to represent the underlying ground truth distribution in the presence of these inherent imprecision. Therefore, we compare the disparity of learning with hard and soft labels quantitatively and qualitatively for a synthetic and a real-world dataset. We show that the application of soft labels leads to improved performance and yields a more regular structure of the internal feature space.
翻译:高质量的数据是现代机器学习的一个关键方面,但是,人类产生的标签受到标签噪音和等级模糊等问题的困扰。我们提出一个问题,即硬标签是否足以在存在这些内在不精确的情况下代表根本的真相分布。因此,我们将学习差异与硬标签和软标签在数量和质量上对合成和真实世界数据集进行比较。我们表明,软标签的应用导致性能的改善,并产生了内部地物空间的更正规的结构。