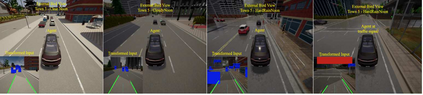
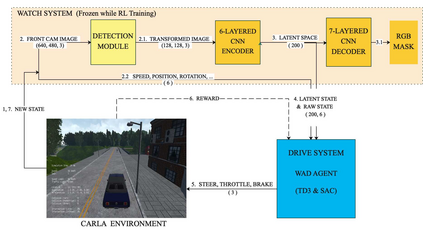
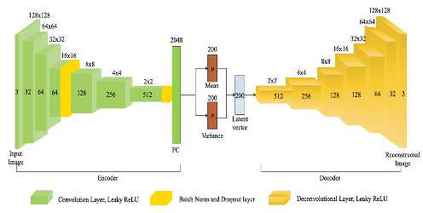
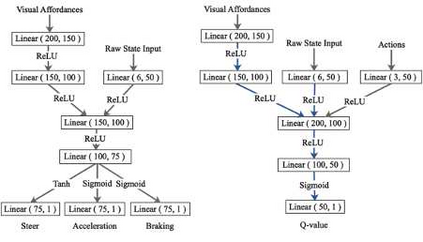
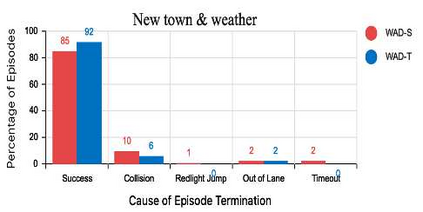
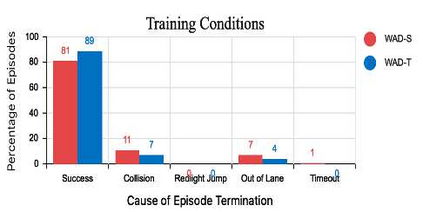
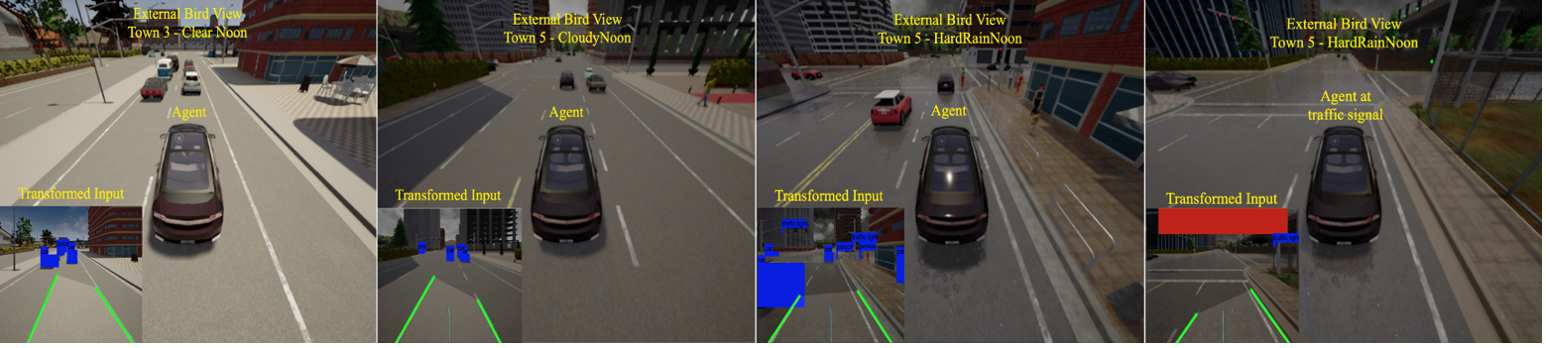
Urban autonomous driving is an open and challenging problem to solve as the decision-making system has to account for several dynamic factors like multi-agent interactions, diverse scene perceptions, complex road geometries, and other rarely occurring real-world events. On the other side, with deep reinforcement learning (DRL) techniques, agents have learned many complex policies. They have even achieved super-human-level performances in various Atari Games and Deepmind's AlphaGo. However, current DRL techniques do not generalize well on complex urban driving scenarios. This paper introduces the DRL driven Watch and Drive (WAD) agent for end-to-end urban autonomous driving. Motivated by recent advancements, the study aims to detect important objects/states in high dimensional spaces of CARLA and extract the latent state from them. Further, passing on the latent state information to WAD agents based on TD3 and SAC methods to learn the optimal driving policy. Our novel approach utilizing fewer resources, step-by-step learning of different driving tasks, hard episode termination policy, and reward mechanism has led our agents to achieve a 100% success rate on all driving tasks in the original CARLA benchmark and set a new record of 82% on further complex NoCrash benchmark, outperforming the state-of-the-art model by more than +30% on NoCrash benchmark.
翻译:城市自主驾驶是一个需要解决的开放和具有挑战性的问题,因为决策系统必须说明多种动态因素,如多试剂互动、不同场景感、复杂的道路地形和其他很少发生的现实世界事件等。另一方面,通过深入强化学习(DRL)技术,代理商已经学到了许多复杂的政策。他们还在各种Atari运动会和Deepmind的阿尔法戈中取得了超人水平的表演。然而,目前的DRL技术并没有在复杂的城市驾驶方案上一概而知。本文介绍了DRL驱动的观察和驱动(WAD)代理商,用于最终到最终的城市自主驾驶。受最近进展的推动,研究的目的是在CARLA的高度空间探测重要对象/状态并从中提取潜在状态。此外,根据TD3和SAC的方法向WAD代理商传递潜在的状态信息,以学习最佳驾驶政策。我们的新办法利用了较少的资源,逐步学习不同的驾驶任务、硬式终止政策以及奖赏机制,使我们的代理商们在推进82-C标准基准中取得了100%的成功率,而没有在82-CBRAA的新基准中进一步推进了82基准。