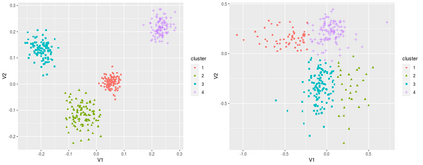
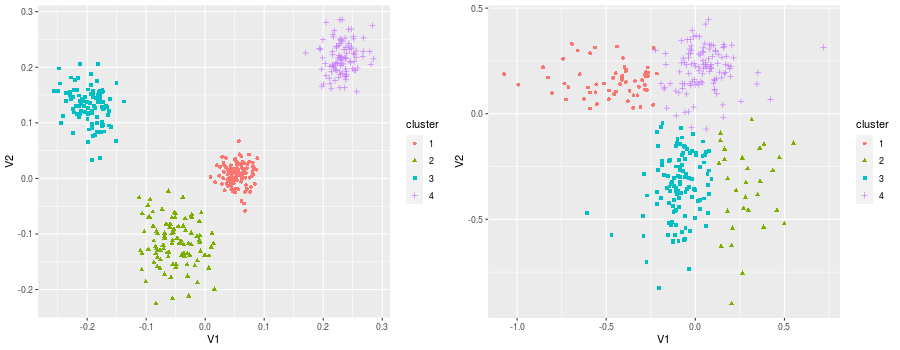
Federated learning (FL) can protect data privacy in distributed learning since it merely collects local gradients from users without access to their data. However, FL is fragile in the presence of heterogeneity that is commonly encountered in practical settings, e.g., non-IID data over different users. Existing FL approaches usually update a single global model to capture the shared knowledge of all users by aggregating their gradients, regardless of the discrepancy between their data distributions. By comparison, a mixture of multiple global models could capture the heterogeneity across various users if assigning the users to different global models (i.e., centers) in FL. To this end, we propose a novel multi-center aggregation mechanism . It learns multiple global models from data, and simultaneously derives the optimal matching between users and centers. We then formulate it as a bi-level optimization problem that can be efficiently solved by a stochastic expectation maximization (EM) algorithm. Experiments on multiple benchmark datasets of FL show that our method outperforms several popular FL competitors. The source code are open source on Github.
翻译:联邦学习(FL) 可以在分布式学习中保护数据隐私,因为它只是从用户那里收集本地梯度,而用户却无法获得数据。然而,FL在实际环境中通常遇到的多种差异性情况下是脆弱的,例如不同用户的非IID数据。现有的FL方法通常更新一个单一的全球模型,通过汇总其梯度来获取所有用户共享的知识,而不论其数据分布之间的差异。相比之下,多种全球模型的混合组合可以捕捉不同用户之间的异质性,如果将用户分配到不同全球模型(即中心)的FL。为此目的,我们提议了一个创新的多中心汇总机制。它从数据中学习多种全球模型,同时获得用户和中心之间的最佳匹配。然后,我们将它编成一个双级优化问题,通过对等预期最大化算法(EM) 算法可以有效解决。关于多种基准数据集的实验表明,我们的方法优于几个受欢迎的FL竞争者。源码是Github的开放源码。