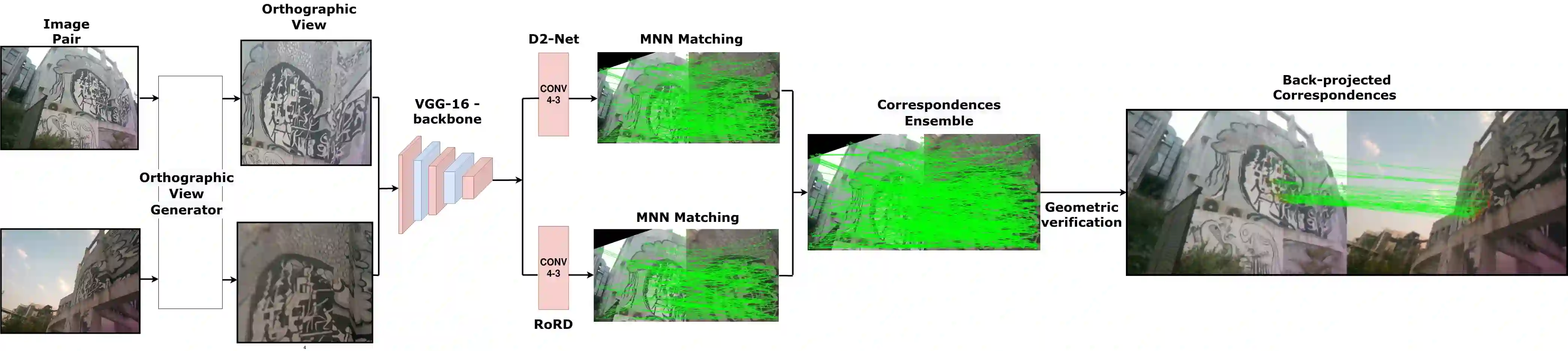
The use of local detectors and descriptors in typical computer vision pipelines work well until variations in viewpoint and appearance change become extreme. Past research in this area has typically focused on one of two approaches to this challenge: the use of projections into spaces more suitable for feature matching under extreme viewpoint changes, and attempting to learn features that are inherently more robust to viewpoint change. In this paper, we present a novel framework that combines learning of invariant descriptors through data augmentation and orthographic viewpoint projection. We propose rotation-robust local descriptors, learnt through training data augmentation based on rotation homographies, and a correspondence ensemble technique that combines vanilla feature correspondences with those obtained through rotation-robust features. Using a range of benchmark datasets as well as contributing a new bespoke dataset for this research domain, we evaluate the effectiveness of the proposed approach on key tasks including pose estimation and visual place recognition. Our system outperforms a range of baseline and state-of-the-art techniques, including enabling higher levels of place recognition precision across opposing place viewpoints and achieves practically-useful performance levels even under extreme viewpoint changes.
翻译:在典型的计算机视像管道中,当地探测器和描述器的使用效果良好,直到观点和外观的变化变得极端不同。过去在这一领域的研究通常侧重于应对这一挑战的两种方法之一:在极端观点变化下,将预测用于更适合特征匹配的空间,并试图学习本能更强的特征,以观察变化。在本文中,我们提出了一个新框架,通过数据增强和正方位观点预测,将不同描述器的学习结合起来。我们提议了旋转-紫色地方描述器,通过基于旋转同质谱的培训数据增强学习,以及将香草特征与通过旋转-紫色特征获得的对应物相结合的对应物通信技术。我们使用一系列基准数据集,并为这一研究领域提供新的直言数据集,我们评估了拟议的关键任务方法的有效性,包括作出估计和视觉定位。我们的系统超越了一系列基线和状态技术,包括使对立观点的定位更加精确,并甚至在极端观点变化下实现实际使用的性能水平。