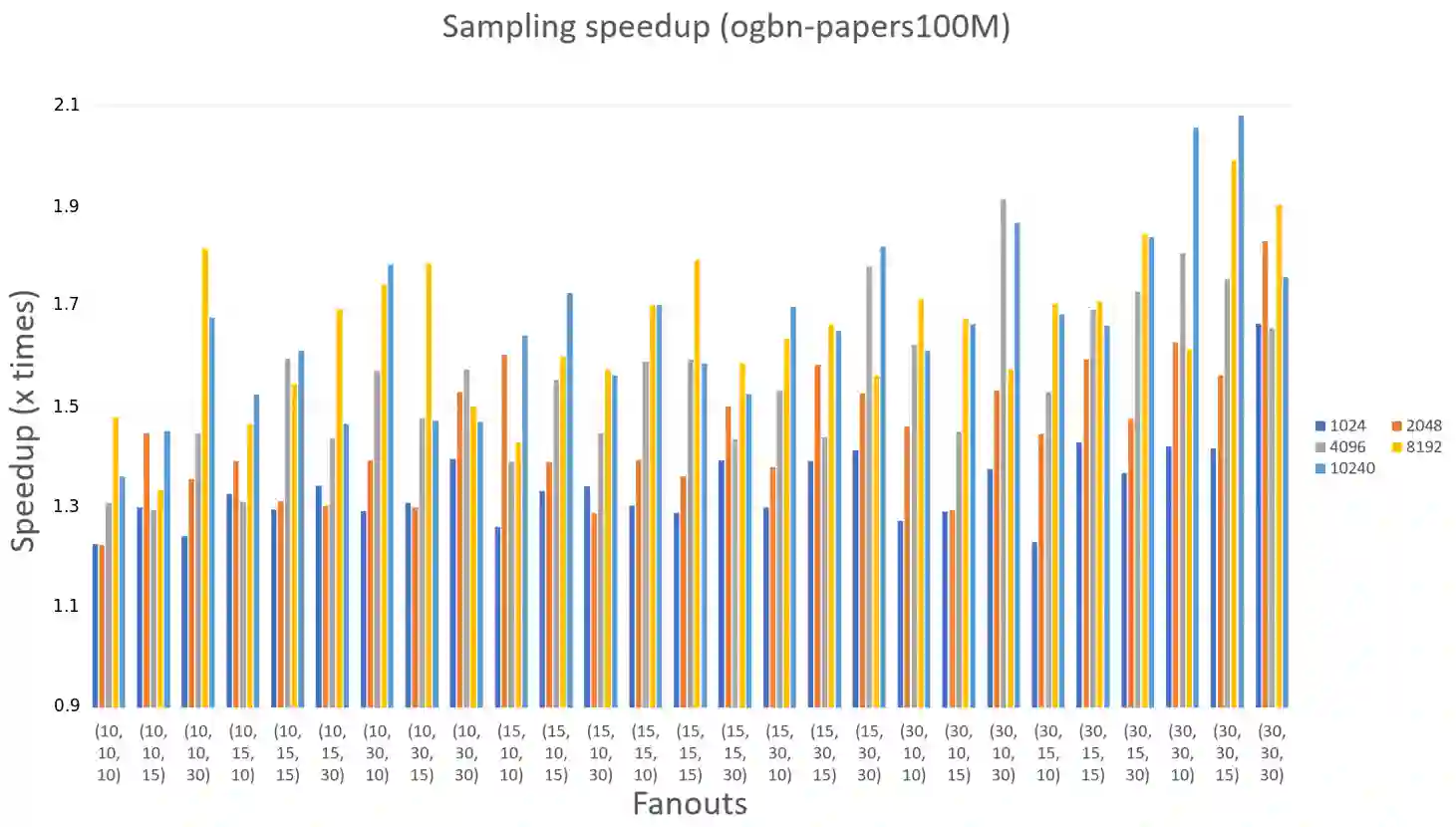
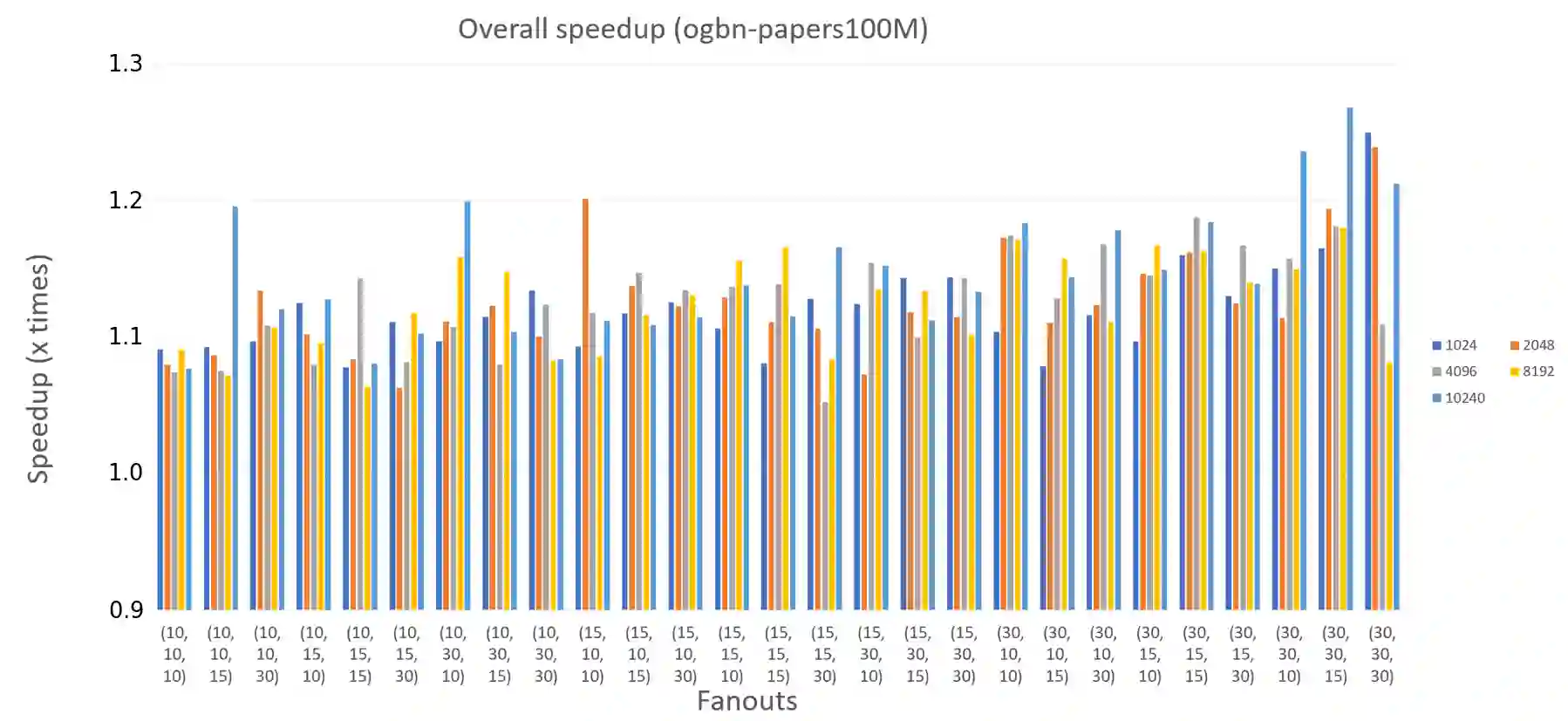
Training Graph Neural Networks(GNNs) on a large monolithic graph presents unique challenges as the graph cannot fit within a single machine and it cannot be decomposed into smaller disconnected components. Distributed sampling-based training distributes the graph across multiple machines and trains the GNN on small parts of the graph that are randomly sampled every training iteration. We show that in a distributed environment, the sampling overhead is a significant component of the training time for large-scale graphs. We propose FastSample which is composed of two synergistic techniques that greatly reduce the distributed sampling time: 1)a new graph partitioning method that eliminates most of the communication rounds in distributed sampling , 2)a novel highly optimized sampling kernel that reduces memory movement during sampling. We test FastSample on large-scale graph benchmarks and show that FastSample speeds up distributed sampling-based GNN training by up to 2x with no loss in accuracy.
翻译:暂无翻译