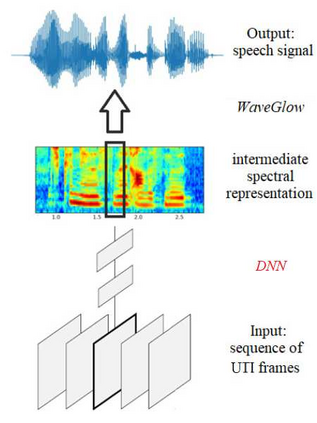
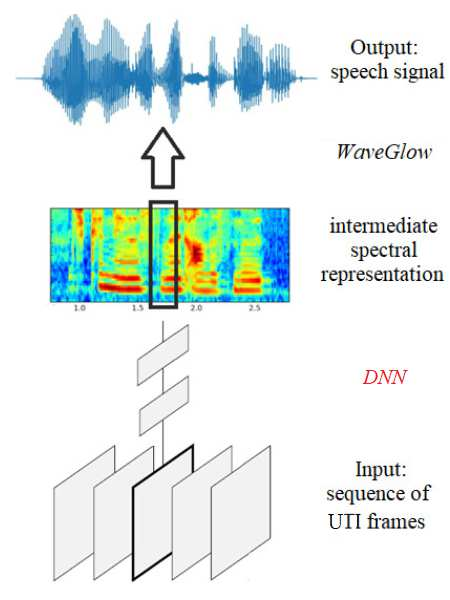
Articulatory-to-acoustic mapping seeks to reconstruct speech from a recording of the articulatory movements, for example, an ultrasound video. Just like speech signals, these recordings represent not only the linguistic content, but are also highly specific to the actual speaker. Hence, due to the lack of multi-speaker data sets, researchers have so far concentrated on speaker-dependent modeling. Here, we present multi-speaker experiments using the recently published TaL80 corpus. To model speaker characteristics, we adjusted the x-vector framework popular in speech processing to operate with ultrasound tongue videos. Next, we performed speaker recognition experiments using 50 speakers from the corpus. Then, we created speaker embedding vectors and evaluated them on the remaining speakers. Finally, we examined how the embedding vector influences the accuracy of our ultrasound-to-speech conversion network in a multi-speaker scenario. In the experiments we attained speaker recognition error rates below 3\%, and we also found that the embedding vectors generalize nicely to unseen speakers. Our first attempt to apply them in a multi-speaker silent speech framework brought about a marginal reduction in the error rate of the spectral estimation step.
翻译:脉动到声波映射图试图从脉动的录音中重建语音,例如超声波视频。就像语音信号一样,这些录音不仅代表语言内容,而且非常具体地代表实际发言者。因此,由于缺乏多声频数据集,研究人员迄今集中于以发言者为依存的模型。在这里,我们用最近出版的 TaL80 文体展示了多声频实验。对于示范演讲者特点,我们调整了在语音处理中流行的X-矢量框架,以便使用超声波舌头视频操作。接下来,我们用该文体的50个发言者进行了语音识别实验。然后,我们创建了扩音器嵌入矢量,并对其余发言者进行了评估。最后,我们研究了矢量嵌入如何影响我们超声波到声频转换网络在多声波假设中的准确性。在实验中,我们将发言者识别误差率控制在3 ⁇ 以下,我们还发现嵌入矢量的矢量非常接近隐形者。我们第一次尝试将其应用于多频谱光度的静音框架。我们试图将其应用于多声波波波度降低率。