
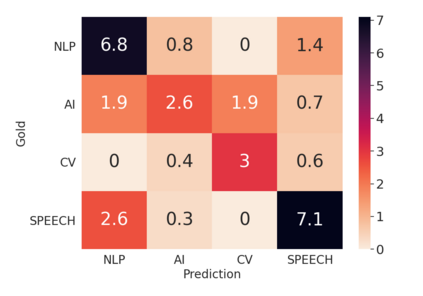
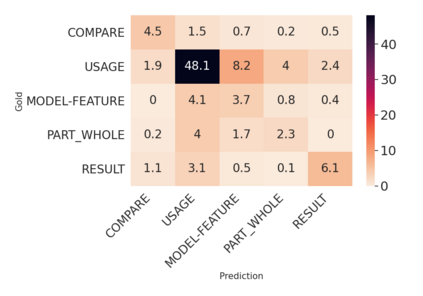
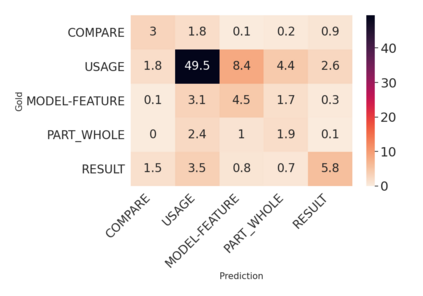
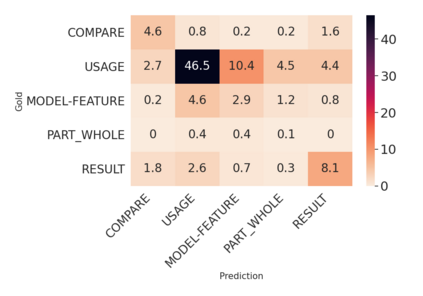
Over the last five years, research on Relation Extraction (RE) witnessed extensive progress with many new dataset releases. At the same time, setup clarity has decreased, contributing to increased difficulty of reliable empirical evaluation (Taill\'e et al., 2020). In this paper, we provide a comprehensive survey of RE datasets, and revisit the task definition and its adoption by the community. We find that cross-dataset and cross-domain setups are particularly lacking. We present an empirical study on scientific Relation Classification across two datasets. Despite large data overlap, our analysis reveals substantial discrepancies in annotation. Annotation discrepancies strongly impact Relation Classification performance, explaining large drops in cross-dataset evaluations. Variation within further sub-domains exists but impacts Relation Classification only to limited degrees. Overall, our study calls for more rigour in reporting setups in RE and evaluation across multiple test sets.
翻译:在过去5年中,关于关系提取(RE)的研究在许多新的数据集释放方面取得了广泛进展。与此同时,设置的清晰度减少了,导致可靠的经验性评估更加困难(Taill\'e等人,2020年)。在本文件中,我们提供了对可再生能源数据集的全面调查,并重新审视任务定义和社区采用该定义的情况。我们发现,特别缺乏跨数据集和跨域设置。我们提出了关于两个数据集的科学关系分类的经验性研究。尽管数据重叠很大,但我们的分析显示在批注方面存在重大差异。注释差异对 Relation分类的绩效产生了强烈影响,解释了交叉数据集评估中出现大量下降的原因。在进一步的子领域内部存在差异,但影响程度有限。总体而言,我们的研究要求更严格地报告多个测试数据集的检索和评估。
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


