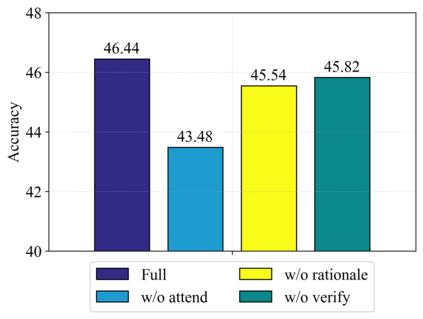
Large pre-trained vision and language models have demonstrated remarkable capacities for various tasks. However, solving the knowledge-based visual reasoning tasks remains challenging, which requires a model to comprehensively understand image content, connect the external world knowledge, and perform step-by-step reasoning to answer the questions correctly. To this end, we propose a novel framework named Interactive Prompting Visual Reasoner (IPVR) for few-shot knowledge-based visual reasoning. IPVR contains three stages, see, think and confirm. The see stage scans the image and grounds the visual concept candidates with a visual perception model. The think stage adopts a pre-trained large language model (LLM) to attend to the key concepts from candidates adaptively. It then transforms them into text context for prompting with a visual captioning model and adopts the LLM to generate the answer. The confirm stage further uses the LLM to generate the supporting rationale to the answer, verify the generated rationale with a cross-modality classifier and ensure that the rationale can infer the predicted output consistently. We conduct experiments on a range of knowledge-based visual reasoning datasets. We found our IPVR enjoys several benefits, 1). it achieves better performance than the previous few-shot learning baselines; 2). it enjoys the total transparency and trustworthiness of the whole reasoning process by providing rationales for each reasoning step; 3). it is computation-efficient compared with other fine-tuning baselines.
翻译:然而,解决基于知识的视觉推理任务仍具有挑战性,这需要一种模型来全面理解图像内容,将外部世界知识连接起来,并逐步进行推理,以正确回答问题。为此,我们提议了一个名为“互动促进视觉理性”的新框架,用于以知识为基础的少见视觉推理。光学研究包含三个阶段,即查看、思考和确认。观察阶段扫描图像,并以视觉认知模型为视觉概念候选人提供依据。思维阶段采用预先培训的大语言模型(LLLM),以便适应候选人的关键概念。然后将它们转换成文字背景,以视觉说明模型提示,采用LLM来生成答案。确认阶段还利用LM(IPVM)来产生支持答案的理由,用跨模式分类来核实产生的理由,并确保其合理性能够一致地推断预测产出。我们对一系列基于知识的视觉推理的数据集进行了实验。我们发现IPVR(LLLM)具有几种更好的推理学原理,而它比先前的推理更精确的推理,它比以往的推理得更精确的推理。